
-
统一模型:Text-to-Text的生成式预训练模型; -
统一任务:Prompt统一(重构)了不同的NLP任务间的差异,不同prompt可以代表不同的任务。 -
统一应用:拿来即用,prompt自适应后直接进行zero/few-shot测试。
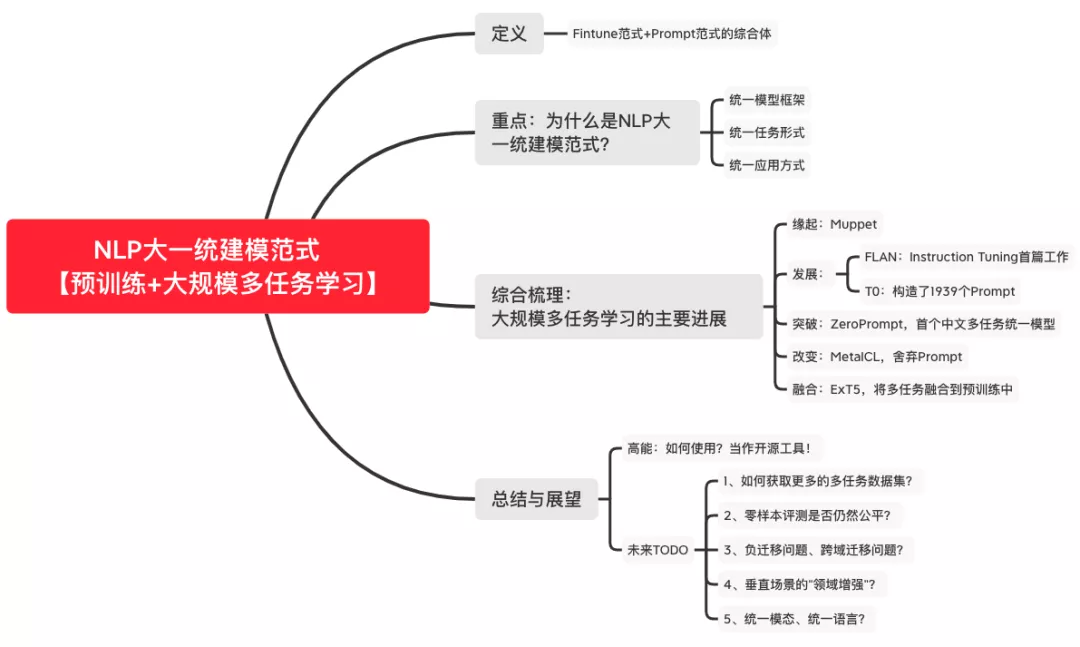
最后,需要再次强调:“预训练+大规模多任务学习”这一范式,在应用层面,更像是一个“开源工具”,可以在更广泛的任务上直接使用。而这些:得益于zero/few-shot性能的大幅提升。
当然,对于这一范式,仍然有不少TODO:
1、如何获取更多的多任务数据集?
当前的多任务数据集规模仍然受限,需要更大规模多任务数据的构建。但由于prompt统一了任务形式,或许我们可以构建一个良性循环系统:
-
在日益多样化的任务集合上训练一些更强大的模型,然后在循环中使用这些模型来创建更具挑战的数据集。如此循环下去。。。
2、零样本评测是否仍然公平?
随着在许多现有任务上训练的多任务模型越来越普遍,保证模型没有看到类似任务示例将变得越来越困难。在这种情况下,少样本学习或完全监督设置可能成为首选的评估范式。
3、负迁移问题、跨域迁移问题?
UnifiedSKG的full-shot实验表明“多任务微调仍然差于单任务微调。那么:负迁移问题是否无法避免(特别是在full-shot场景下)?如何选择更好的多任务分布?
同时在ZeroPrompt相关实验表明:跨任务迁移的zeroshot性能,并不总是随着任务规模的增加而持续提升。随着多任务数据的增加,跨域迁移问题如何降低?
4、垂直场景的“领域增强”?
受到UnifiedSKG的启发,我们是否可以针对某一类领域任务进行大规模多任务学习呢?不过,首要困难还是(有标注)多任务数据的收集。
5、统一模态、统一语言?
大规模多任务学习在跨模态、跨语言的统一上,是否可更进一步?比如最近的《Few-shot Learning with Multilingual Language Models》已经在统一语言的工作上迈出一步!
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢