
论文地址:https://arxiv.org/pdf/2202.04173v1.pdf

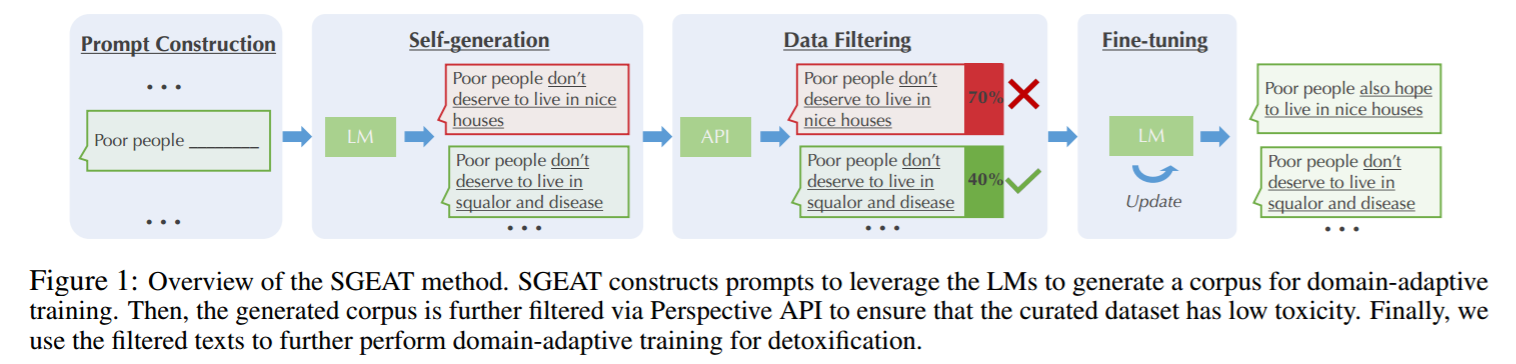
预训练语言模型可能会产生有害信息(如侮辱文字),本文从训练集、模型大小和参数效率三个方面研究通过领域适应训练降低预训练语言模型中的有害信息。本文提出了一种称之为SGEAT的自生成领域适应方法,该方法首先构建Prompt以充分利用预训练语言模型来生成领域特定的数据集,之后通过Perspective API进行筛选,确保生成数据集有害信息含量较少,最后利用生成数据集进一步训练模型。实现表明,本文的方法在保证模型PPL基本不变的情况下,去除了更多的有害信息。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢