

论文(已收录于ICLR 2022):
https://arxiv.org/abs/2108.00154
代码地址(已开源):
https://github.com/cheerss/CrossFormer
作者单位:浙江大学CAD&CG国家重点实验室、哥伦比亚大学、腾讯
在视觉任务中,跨尺度的注意力机制非常重要。如,同一张图片中不同大小的物体建立关联需要跨尺度的注意力机制;而在实例分割等任务中,为了得出更好的分割结果,也需要建立大尺度的全局特征和小尺度的细粒度特征之间的关联。但现有的视觉Transformer并不拥有建立跨尺度特征的能力。本文分析造成此问题的原因有两方面:
-
现有的Transformer大多把输入图像分成相同大小的图块,然后生成视觉嵌入(embeddings)。因此,同一层中的所有嵌入的尺度总是相同的,本身并不具备跨尺度的特征。
-
为了降低自注意力模块(self-attention)的显存和计算开销,很多现有Transformer会合并相邻的嵌入,让他们共享相同的key/value。因此,此时嵌入本身含有跨尺度的特征,这种合并的操作也会使得他们失去小尺度(细粒度)的特征,从而无法构建跨尺度的注意力。
针对此问题,本文提出基于跨尺度注意力机制的视觉Transformer -– CrossFormer。CrossFormer和PVT等一样采用金字塔式的结构,从而将模型分为了多个不同的阶段(stage),如图1所示。它的核心设计包含跨尺度嵌入层(CEL)和长短距离注意力(L/SDA)两个模块:
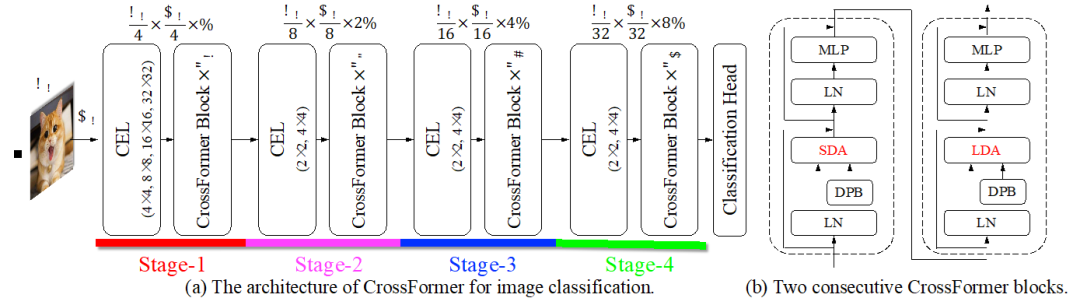
图 1 CrossFormer的整体结构
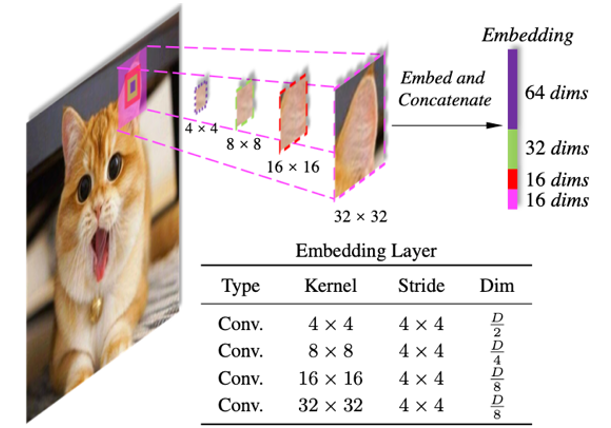
图 2 跨尺度嵌入层Cross-scale Embedding Layer(CEL)
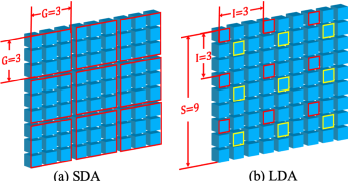
图3 长短距离注意力(Long Short Distance Attention,LSDA)的分组方式。
文中给出了4种不同大小的CrossFormer,它们在图像分类、物体检测、实例分割、语义分割4个具有代表性的视觉任务上超越了其他的视觉Transformer。并且在物体检测、实例分割、语义分割3个任务上涨点非常显著。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢