
【标题】SAFER: Data-Efficient and Safe Reinforcement Learning via Skill Acquisition
【作者团队】Dylan Slack, Yinlam Chow, Bo Dai, Nevan Wichers
【发表日期】2022.2.10
【论文链接】https://arxiv.org/pdf/2202.04849.pdf
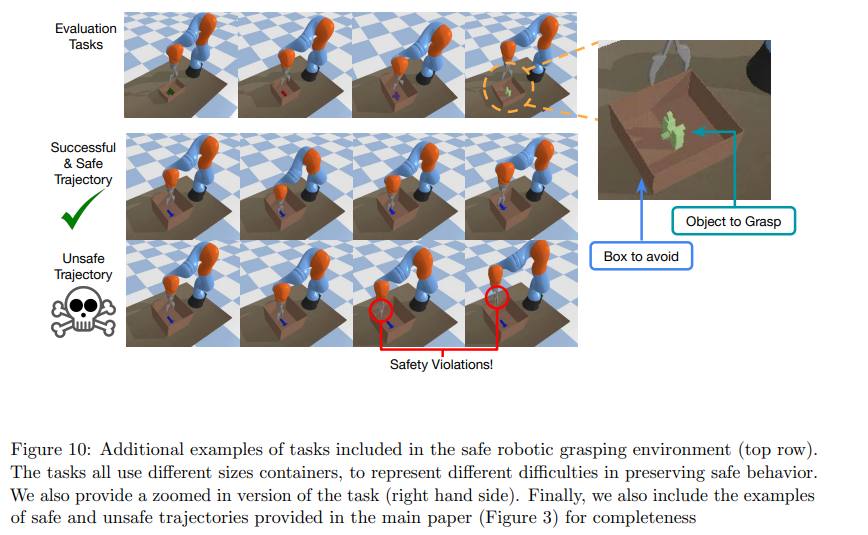
【推荐理由】尽管许多强化学习(RL)问题涉及在难以指定安全约束和稀疏奖励的环境中学习策略,但目前的方法难以获得成功和安全的策略。使用生成性建模从离线数据集中提取有用策略原语的方法最近显示出在这些更复杂的环境中加速RL的前景。然而,研究发现,目前的原始学习方法可能不适合安全策略学习,并且可能会促进不安全行为,因为它们倾向于忽略来自不良行为的数据。为了克服这些问题,本文提出了安全技能优先(SAFER),这是一种在安全约束下加速复杂控制任务策略学习的算法。通过对离线数据集的原则性培训,SAFER学习提取安全的原始技能。在推理阶段,接受过安全培训的政策将学习将安全技能组合成成功的政策。本文从理论上描述了为什么SAFER可以实施安全策略学习,并证明了它在受游戏操作启发的几个复杂的安全关键机器人抓取任务上的有效性,其中SAFER在学习成功的策略和实施安全方面优于基线方法。



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢