
【标题】Offline Reinforcement Learning with Realizability and Single-policy Concentrability
【作者团队】Wenhao Zhan, Baihe Huang, Audrey Huang, Nan Jiang, Jason D. Lee
【发表日期】2022.2.10
【论文链接】https://arxiv.org/pdf/2202.04634.pdf
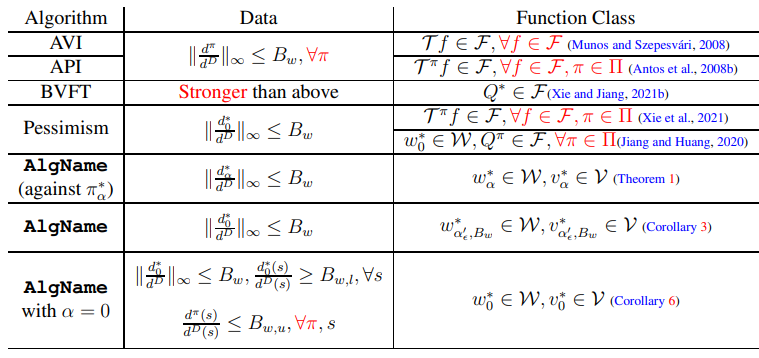
【推荐理由】离线强化学习(RL)的样本效率保证通常依赖于对函数类(如Bellman完备性)和数据覆盖率(如所有策略集中性)的有力假设。尽管最近做出了放松这些假设的研究,但现有的工作只能放松这两个因素中的一个,而对另一个因素的强大假设则完好无损。作为一个重要的开放性问题,能否在对这两个因素的假设较弱的情况下实现样本有效的离线RL显得尤为重要,本文以肯定的方式回答这个问题。通过分析了一个基于MDP原始-对偶公式的简单算法,其中对偶变量(折扣入住率)使用密度比函数对离线数据进行建模。通过适当的正则化证明了该算法在仅可实现和单策略集中的情况下,具有多项式样本复杂度。该研究还提供了基于不同假设的替代分析,以阐明离线RL的原始-对偶算法的性质。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢