
【标题】Adversarially Trained Actor Critic for Offline Reinforcement Learning
【作者团队】Ching-An Cheng, Tengyang Xie, Nan Jiang, Alekh Agarwal
【发表日期】2022.2.5
【论文链接】https://arxiv.org/pdf/2202.02446.pdf
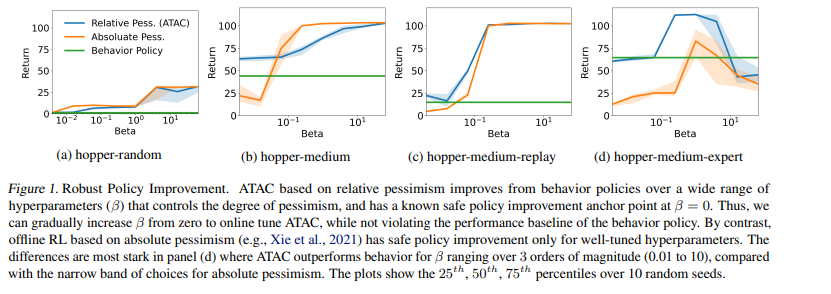
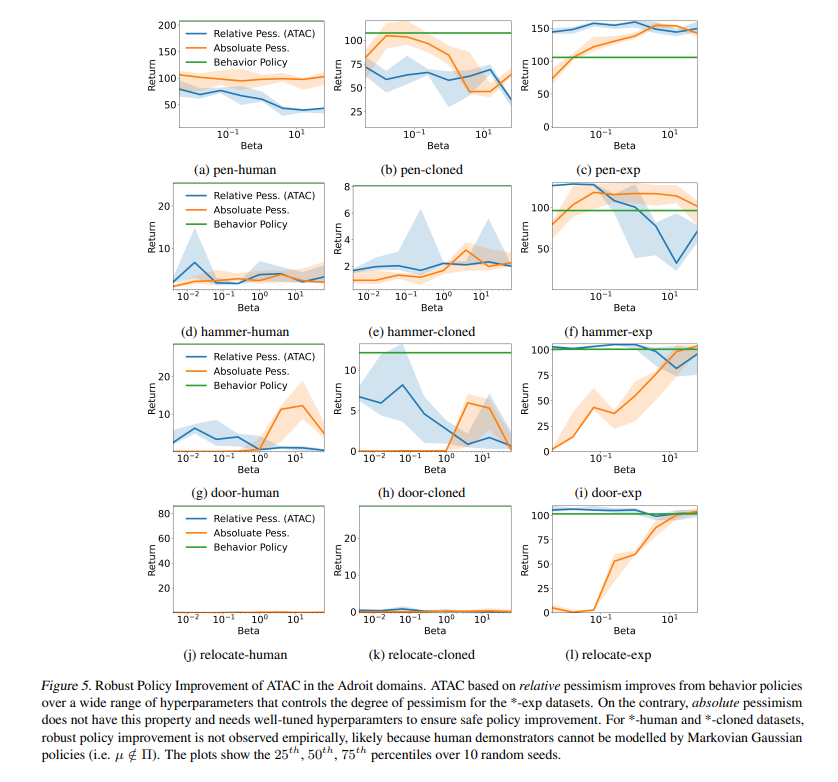
【推荐理由】本文提出了 Adversarially Trained Actor Critic (ATAC),这是一种新的无模型算法,用于在数据覆盖不足的情况下进行离线强化学习,基于离线 RL 的两人 Stackelberg 游戏框架:策略参与者与经过对抗训练的价值评论家竞争,后者发现参与者不如数据收集行为策略的数据一致场景。研究表明,当参与者在两人游戏中没有后悔时,运行 ATAC 产生的策略可证明: 1)在广泛的超参数范围内优于行为策略,以及 2)以适当的方式与数据覆盖的最佳策略竞争选择的超参数。与现有研究相比,值得注意的是,该框架既为通用函数逼近提供了理论保证,又为可扩展到复杂环境和大型数据集的深度 RL 实现提供了保障。在 D4RL 基准测试中,ATAC 在一系列连续控制任务上始终优于最先进的离线 RL 算法。



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢