
【标题】Model-Based Offline Meta-Reinforcement Learning with Regularization
【作者团队】Sen Lin, Jialin Wan, Tengyu Xu, Yingbin Liang, Junshan Zhang
【发表日期】2022.2.7
【论文链接】https://arxiv.org/pdf/2202.02929.pdf
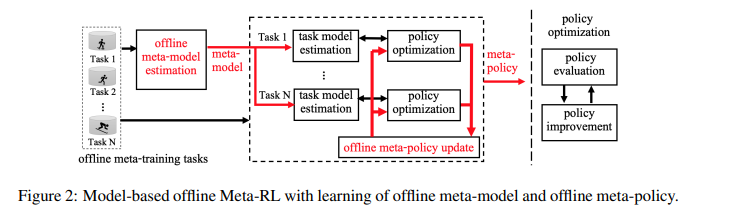
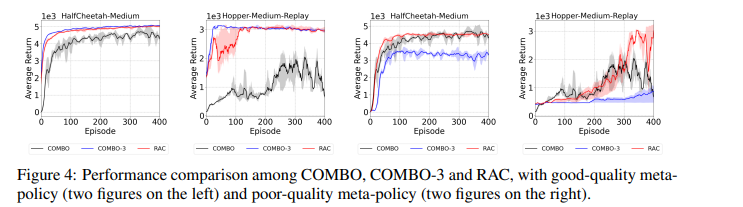
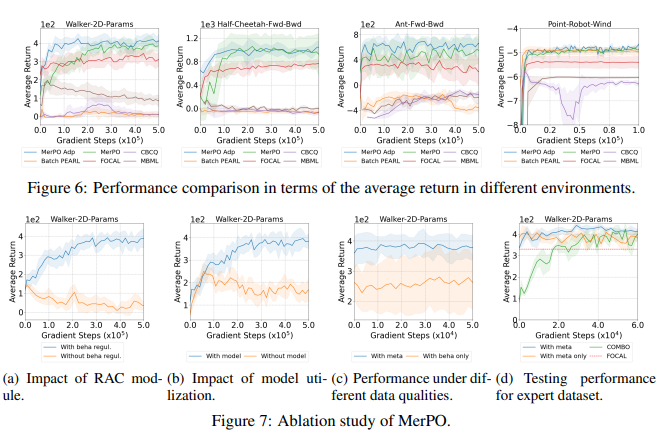
【推荐理由】现有的离线强化学习(RL)方法面临一些主要挑战,尤其是学习策略和行为策略之间的分布变化。离线元RL正在成为解决这些挑战的一种有前途的方法,旨在从一系列任务中学习信息丰富的元策略。然而,正如研究所示,在数据集质量良好的任务上,离线元RL方法可能优于离线单任务RL方法。基于此,本文探索了基于模型的离线元RL和正则化策略优化(MerPO),它学习了一个元模型,用于有效的任务结构推理,以及一个信息元策略,用于安全探索分布外状态的行动。本文设计了一种新的基于元正则化模型的角色-批评(RAC)方法,用于任务内策略优化,作为MerPO的关键构建块,使用保守策略评估和正则化策略改进;内在权衡是通过在两个正则化器之间取得适当的平衡来实现的,分别为基于行为策略和元策略。该研究从理论上证明,学习策略比行为策略和元策略都有保证的改进,从而确保通过离线元RL提高新任务的性能。实验证实了MerPO比现有离线Meta-RL方法优越的性能。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢