

论文标题:NASViT: Neural Architecture Search for Efficient Vision Transformers with Gradient Conflict aware Supernet Training
论文链接:https://openreview.net/forum?id=Qaw16njk6L
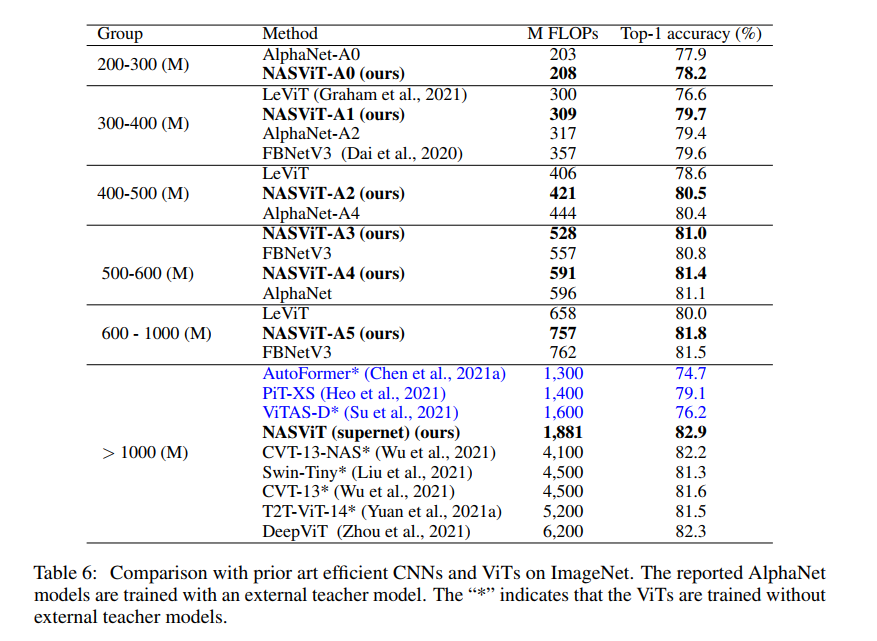
设计准确高效的视觉Transformer (ViT) 是一项非常重要但具有挑战性的任务。基于超网的一次性神经架构搜索 (NAS) 可实现快速架构优化,并在卷积神经网络 (CNN) 上取得了最先进的 (SOTA) 结果。然而,直接应用基于超网的 NAS 来优化 ViT 会导致性能不佳 - 与训练单个 ViT 相比更糟。在这项工作中,我们观察到性能不佳是由于梯度冲突问题:ViTs 中不同子网络的梯度与超网络的梯度冲突比 CNN 更严重,这导致训练过早饱和和收敛性较差。为了缓解这个问题,我们提出了一系列技术,包括梯度投影算法、可切换层缩放设计以及简化的数据增强和正则化训练方案。所提出的技术显着提高了所有子网络的收敛性和性能。我们发现的混合 ViT 模型系列,称为 NASViT,在 ImageNet 上从 200M 到 800M FLOPs 的 top-1 准确率从 78.2% 到 81.8%,并且优于所有现有技术的 CNN 和 ViT,包括 AlphaNet 和 LeViT 等。当转移到语义在分割任务中,NASViT 在 Cityscape 和 ADE20K 数据集上的表现也优于以前的骨干网,仅在 5GFLOPs 上分别实现了 73.2% 和 37.9% 的 mIoU。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢