
上海人工智能实验室联合商汤科技共同提出一种新的 UniFormer(Unified Transformer)框架, 它能够将卷积与自注意力的优点通过 Transformer 进行无缝集成。与经典的 Transformer 模块不同,UniFormer 模块的相关性聚合在浅层与深层分别配备了局部全局token,能够同时解决冗余与依赖问题,实现了高效的特征学习。包括 ICLR2022 接受的 video backbone,以及为下游密集预测任务设计的拓展版本,UniFormer 整套框架在各种任务上都能表现出比现有 SOTA 模型更好的性能。

论文标题:
UniFormer: Unified Transformer for Efficient Spatiotemporal Representation Learning
论文链接:
https://arxiv.org/abs/2201.04676
扩展版本:
UniFormer: Unifying Convolution and Self-attention for Visual Recognition
代码链接:
https://github.com/Sense-X/UniFormer
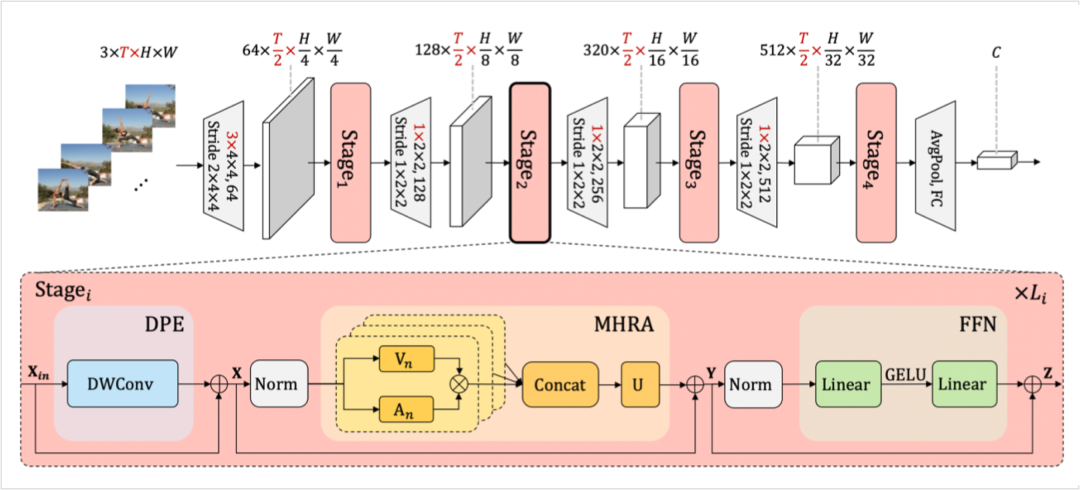
图4:模型整体框架,标红维度仅对 video 输入作用,对 image 输入都可视作 1
模型整体框架如上图所示,借鉴了 CNN 的层次化设计,每层包含多个 Transformer 风格的 UniFormer block。每个 UniFormer block 主要由三部分组成,动态位置编码 DPE、多头关系聚合器 MHRA 及 Transformer 必备的前馈层 FFN。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢