
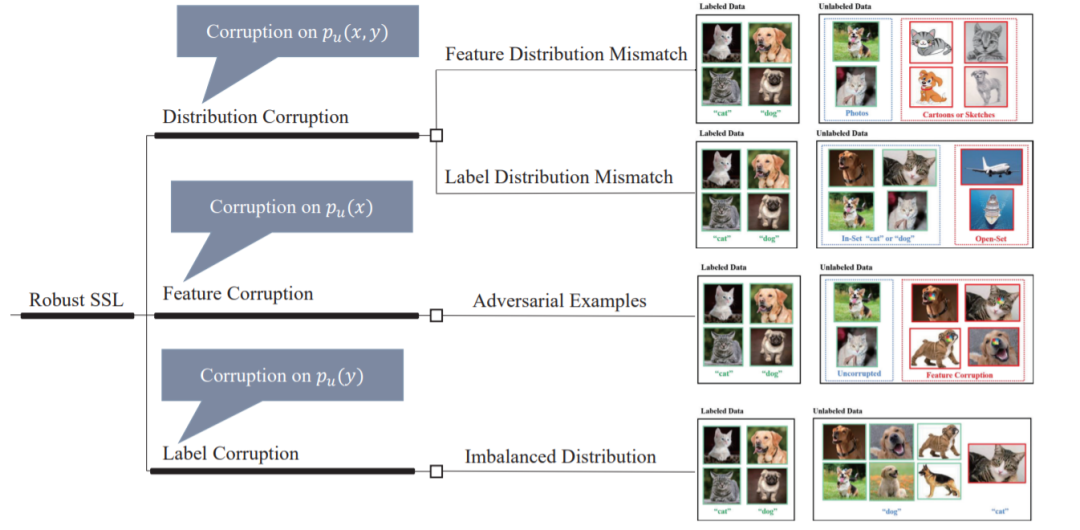
半监督学习(Semi-supervised learning, SSL)是机器学习的一个分支,其目的是在标签不足的情况下利用未标记的数据来提高学习性能。最近,具有深度模型的SSL已被证明在标准基准测试任务上是成功的。然而,在现实应用中,它们仍然容易受到各种健壮性威胁,因为这些基准提供了完美的无标签数据,而在现实场景中,无标签数据可能被破坏。许多研究人员指出,在利用被破坏的未标记数据后,SSL会遭受严重的性能退化问题。因此,迫切需要研发SSL算法,能够稳健地处理损坏的未标记数据。为了充分理解健壮的SSL,我们进行了一项调查研究。我们首先从机器学习的角度阐明了健壮SSL的正式定义。然后,我们将鲁棒性威胁分为三类: i) 分布损坏,即未标记数据分布与标记数据不匹配; ii) 特征损坏,即未标记例子的特征被敌方攻击; iii) 标签损坏,即未标签数据的标签分布不均衡。在这个统一的分类下,我们提供了一个全面的综述和讨论最近的工作,重点关注这些问题。最后,我们提出了在健壮SSL中可能的有前途的方向,为未来的研究提供了见解。
论文链接:
https://arxiv.org/abs/2202.05975
-
我们瞄准了关键但却被忽视的健壮SSL问题。从机器学习的角度,给出了健壮SSL的形式化定义。该定义不仅具有足够的普遍性,可以包括现有的健壮SSL方法,而且具有足够的特殊性,可以阐明健壮SSL的目标是什么。 -
我们指出,无标签数据损坏是对SSL的健壮性威胁,并提供了一个完整的分类无标签数据损坏类型,即分布损坏、特征损坏和标签损坏。我们给出了每个问题的形式化定义和标准化描述。这有助于其他研究人员清楚地理解健壮的SSL。 -
对于每一种健壮性威胁,我们都对最近构建健壮SSL模型的工作进行了全面的回顾。他们的关系,pros, and cons也被讨论。您可以很快掌握健壮SSL的前沿思想。 -
在现有的健壮SSL研究之外,我们提出了几个有前景的未来方向,如健壮的通用数据类型,健壮的复合弱监督数据,健壮的SSL与领域知识,在动态环境中学习,以及构建真实的数据集。我们希望它们能够为健壮的SSL研究提供一些见解
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢