
摘要
在深度神经网络之后,以多头自注意力机制为核心的Vision Transformer因其对输入全局关联的强大建模能力得到了广泛应用和研究。尽管现有研究在模型结构、损失函数、训练机制等方面提出了诸多改进,但少有研究对Vision Transformer的工作机制进行了深入探索。本文为ICLR 2022中的亮点论文之一,提供了不同解释来帮助理解Vision Transformer (ViT)的优良特性:1)多头自注意力机制不仅提高了精度,而且通过使损失的超平面变得平坦,提高了泛化程度;2)多头自注意力机制和卷积模块表现出相反的行为。例如,多头自注意力机制是低通滤波器,而卷积模块是高通滤波器;3)多层的神经网络的行为就像一系列小的个体模型的串联;4)最后阶段的卷积模块在预测中起着关键作用。

论文链接:https://openreview.net/pdf?id=D78Go4hVcxO
代码链接:https://github.com/xxxnell/how-do-vits-work
动机
作为ViT模型的核心组件,多头自注意力机制(MSAs)能够在计算机视觉领域的诸多模型中得到了广泛的应用,且其性能得到了它长期依赖建模能力、弱归纳偏置的保证,获得了诸多研究人员的一致关注。现有研究认为,这一优势也带来了ViT模型在训练数据上过拟合的风险。然而,本文作者从三个方面证实这一风险并不存在:
- What properties of MSAs do we need to improve optimization?
- Do MSAs act like Convs?
- How can we harmonize MSAs with Convs?
技术路线
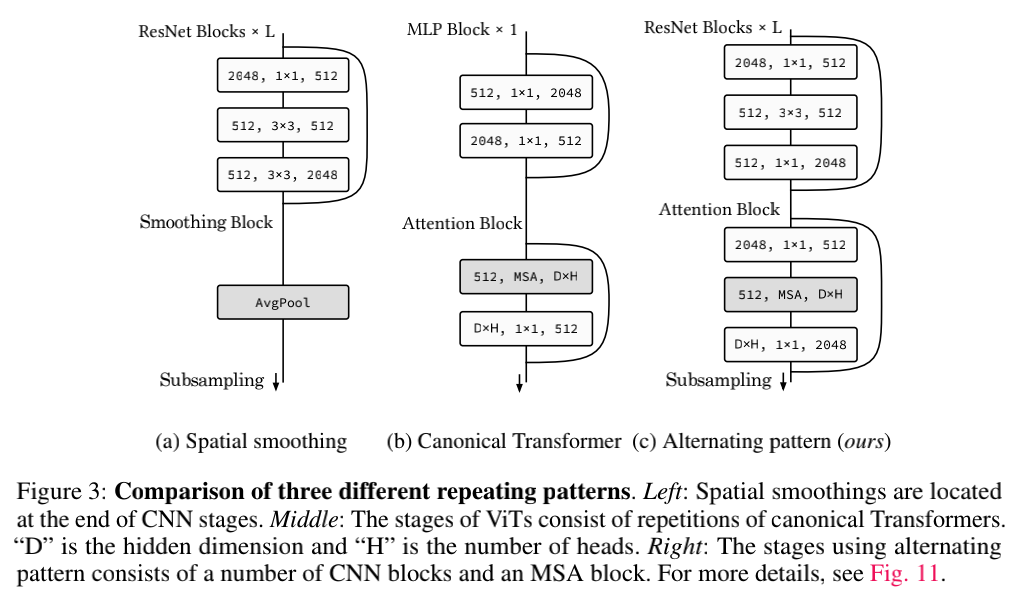
为了探索上述问题,如图3所示,作者对比了ResNet、vanilla ViT、PiT三种常见的计算机视觉模型。
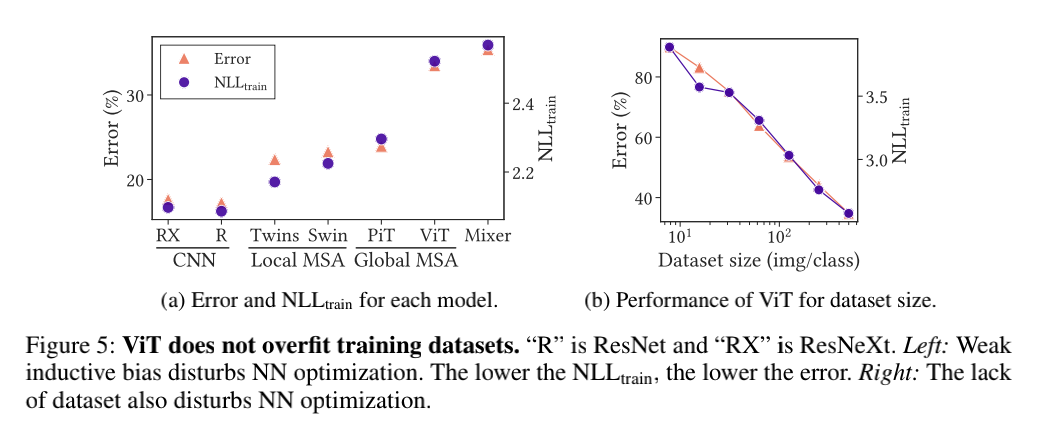
在归纳偏置上,作者首先回答了动机中的关键问题——ViT模型不会在训练数据上过拟合。
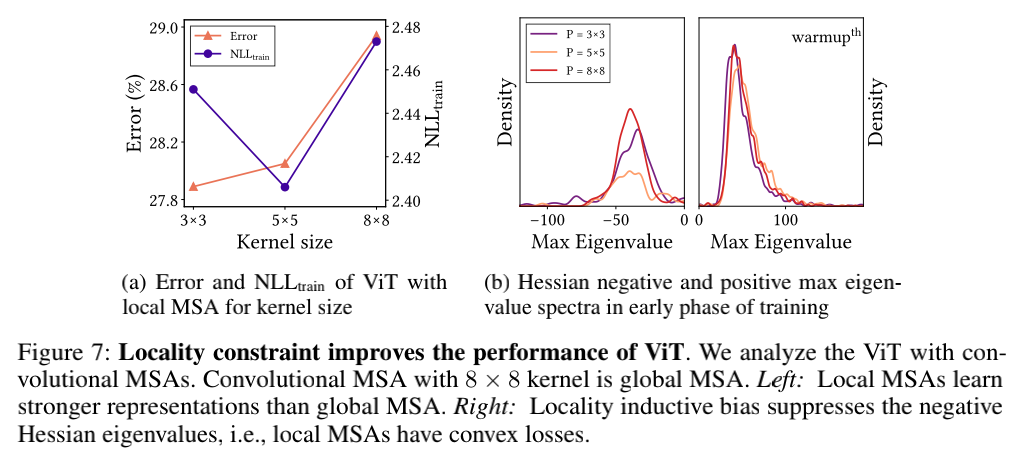
对于第一个问题,作者发现MSAs的关键属性是数据的局部明确性(data specificity)而非长期依赖。
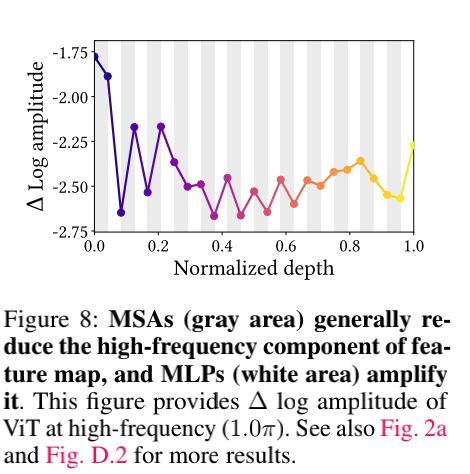
对于第二个问题,作者发现MSAs与卷积模块由两个最大的区别:前者为低通滤波后者为高通滤波,前者叠加特征而后者不叠加。
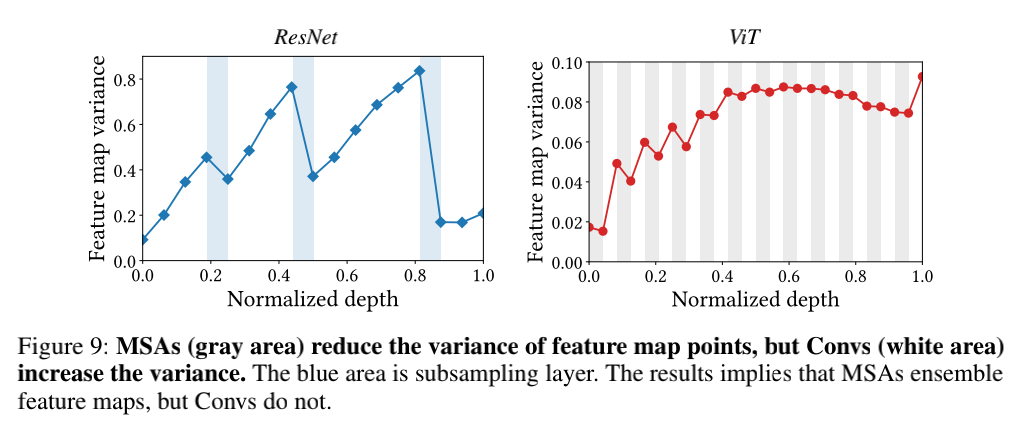
对于第三个问题,作者提出二者的结构设计是实现多头注意力机制与卷积模块协同工作的关键,并提出了一个基础模型,结构如下:
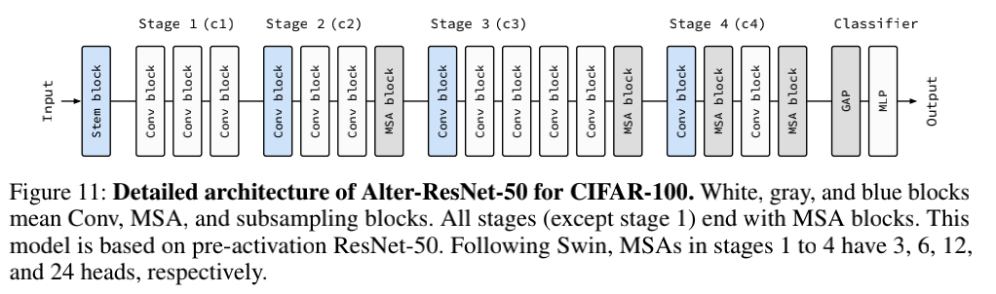
性能对比
本文分别从分类任务的CIFAR-100、CIFAR-100-C两个数据集上进行了模型性能的对比。

总结
本文证明了多头注意力机制不仅是广义的卷积操作,而且是与卷积模块互补的空间全局依赖建模机制。多头注意力机制通过集成特征和平滑损失超平面来帮助神经网络学习强表示。因为这项工作的主要目标是为了研究视觉Transformer中多头注意力机制的本质,作者保留了卷积神经网民的体系结构并结合AlterNet中的多头注意力机制提出了一个新的基准模型。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢