Transformer 在自然语言处理、计算机视觉和音频处理方面取得了巨大的成功。作为其核心组件之一,softmax 注意力有助于捕获长程依赖关系,但由于序列长度的二次空间和时间复杂度而禁止其扩展。研究者通常采用核(Kernel)方法通过逼近 softmax 算子来降低复杂度。然而,由于近似误差,它们的性能在不同的任务 / 语料库中有所不同,与普通的 softmax 注意力相比,其性能会下降。
研究者认为 softmax 算子是主要障碍,而对 softmax 高效而准确的逼近很难实现,因此很自然地提出一个问题:我们能否用线性函数代替 softmax 算子,同时保持其关键属性?
通过对 softmax 注意力的深入研究,研究发现了影响其经验性能的两个关键性质:
(ii) 一种非线性重重加权方案,可以聚集注意力矩阵分布。
这些发现揭示了当前方法的一些新见解。例如,线性 transformer 使用指数线性单元激活函数来实现属性 (i)。然而,由于缺乏重重加权(re-weighting )方案,表现不佳。
本文中,来自商汤、上海人工智能实验室等机构的研究者提出了一种称为 COSFORMER 的线性 transformer,它能同时满足上述两个特性。具体来说,在计算相似度分数之前,该研究将特征传递给 ReLU 激活函数来强制执行非负属性。通过这种方式使得模型避免聚合负相关的上下文信息。此外,该研究还基于余弦距离重加权机制来稳定注意力权值。这有助于模型放大局部相关性,而局部相关性通常包含更多自然语言任务的相关信息。
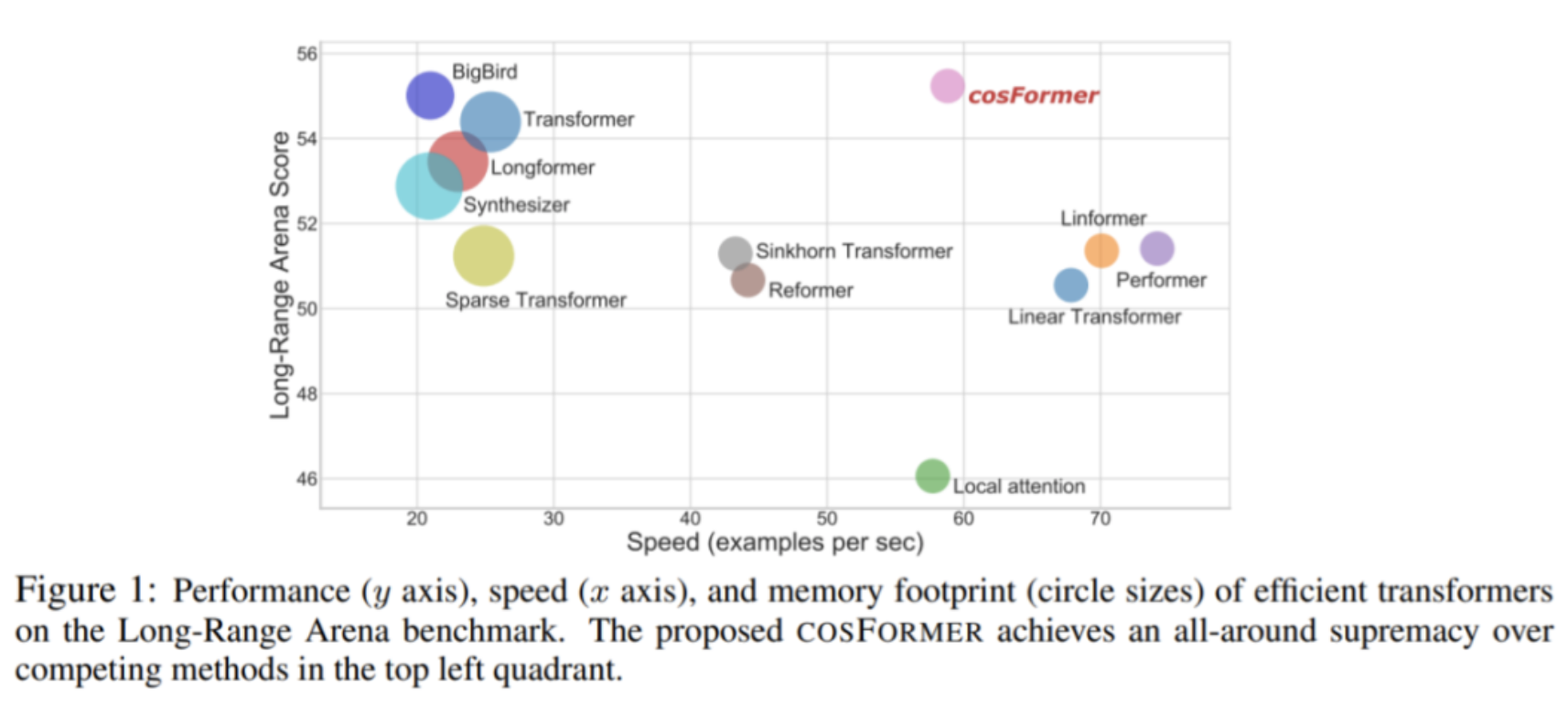
在语言建模和文本理解任务的大量实验证明 COSFORMER 方法的有效性,并且在长序列 Long-Range Arena 基准上实现了 SOTA 性能,这一结果很好地证明了 COSFORMER 在建模长序列输入方面的强大能力。
内容中包含的图片若涉及版权问题,请及时与我们联系删除



评论
沙发等你来抢