
论文标题:Not All Patches are What You Need: Expediting Vision Transformers via Token Reorganizations
论文链接:https://openreview.net/forum?id=BjyvwnXXVn_
代码链接:https://github.com/youweiliang/evit
作者单位:UC San Diego & 香港大学 & 腾讯AI lab
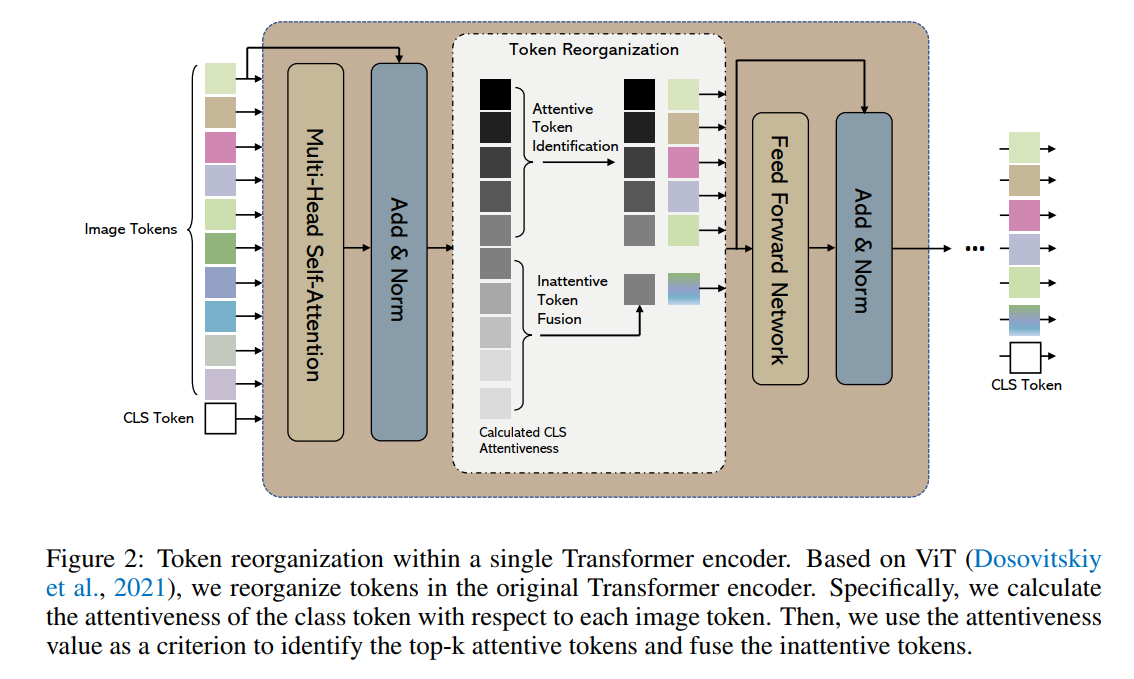
Vision Transformers (ViTs) 将所有图像块作为token,并在其中构建多头自注意力 (MHSA)。完全利用这些图像token会带来冗余计算,因为并非所有token都在 MHSA 中是专心的。示例包括包含语义上无意义或分散注意力的图像背景的标记对 ViT 预测没有积极贡献。在这项工作中,我们建议在 ViT 模型的前馈过程中重新组织图像token,在训练期间将其集成到 ViT 中。对于每个前向推理,我们识别 MHSA 和 FFN(即前馈网络)模块之间的注意力图像token,这是由相应的类token注意力引导的。然后,我们通过保留关注的图像token并融合不关注的图像标记来重组图像token,以加快后续的 MHSA 和 FFN 计算。为此,我们的方法 EViT 从两个角度改进了 ViT。首先,在相同数量的输入图像标记下,我们的方法减少了 MHSA 和 FFN 计算以实现高效推理。例如,DeiT-S 的推理速度提高了 50%,而 ImageNet 分类的识别准确率仅下降了 0.3%。其次,通过保持相同的计算成本,我们的方法使 ViT 能够将更多的图像标记作为输入以提高识别精度,其中图像标记来自更高分辨率的图像。一个例子是,在与普通 DeiT-S 相同的计算成本下,我们将 DeiT-S 的 ImageNet 分类识别准确率提高了 1%。同时,我们的方法没有向 ViT 引入更多参数。在标准基准上的实验证明了我们方法的有效性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢