
这篇论文介绍了谷歌去年在稀疏专家模型上的工作,解决Switch Transformers预训练的变体不稳定或微调不佳问题。

论文地址:https://arxiv.org/pdf/2202.08906.pdf
近年来基于Transformer的大规模预训练模型在NLP中取得了显著的成果,但代价高昂。
基于此,MoE和Swim Transformer已经被提出作为一个能源效率更高的路径,甚至更大和更强大的语言模型。
但是,在广泛的自然语言任务中推进最先进的技术一直受到训练的不稳定性和微调过程中质量的不确定性的阻碍。
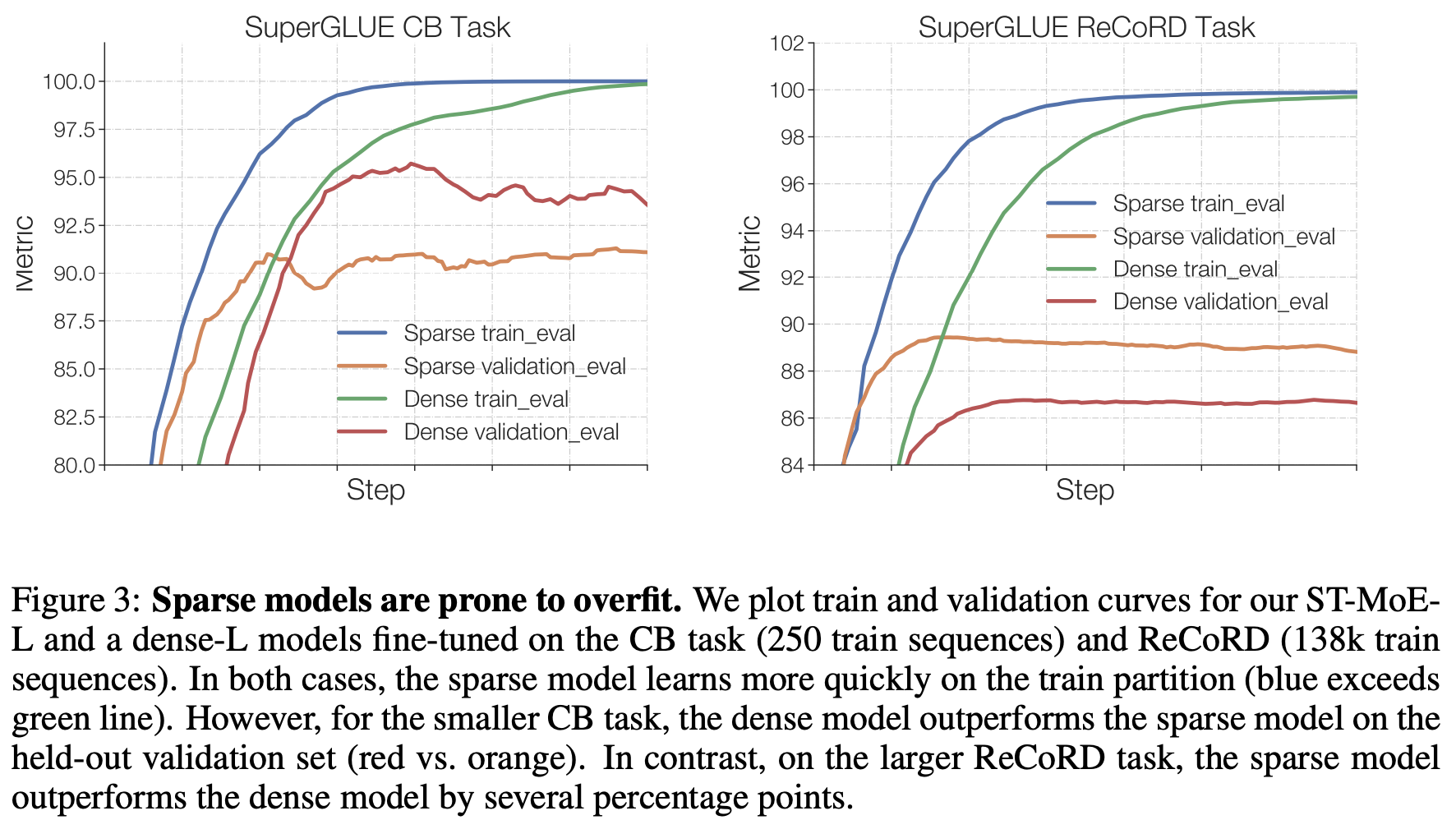
本文主要聚焦这些问题并设计了相应准则。最后,我们将稀疏模型扩展到269B参数,计算成本可与32B密集编码器-解码器Transformer(专家或ST-MoE-32B的稳定可转移混合)相媲美。
稀疏模型首次在迁移学习中实现了最先进的表现,跨越了一系列不同的任务,包括推理(SuperGLUE, ARC Easy, ARC Challenge)、摘要(XSum, CNN-DM)、闭式问答(WebQA, Natural Questions)和逆向构建的任务(Winogrande、ANLI R3)。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢