
摘要
在人工智能领域,构建一个统一的模型以处理多种不同的数据、任务一直是研究人员的追求。然而,其难点在于如何在一个模型中对多种数据进行表达并实现任务特定的语义转换。来自阿里团队的作者在本文中提出了一个统一的多模态预训练范式来实现上述目标。通过这一范式,作者们进一步提出了OFA模型将多种模式、任务统一到一个基于编-解码结构的sequence-to-sequence学习框架中。OFA使用任务指令执行预训练和微调,并没有引入额外的参数模块。实验结果表明,OFA在一系列多模态任务上都达到了新水平,包括图像描述(COCO CIDEr: 149.6)、文本到图像的生成(COCO FID: 10.5)、VQA (test-std acc: 80.02), SNLI-VE(测试acc。 90.20),referring expression comprehension(RefCOCO / RefCOCO+ / RefCOCOg test acc。: 92.93 / 90.10 / 85.20)。通过大量的分析,本文证明了OFA在单模态任务(包括NLU、NLG和图像分类)中与单模态预训练模型(如BERT、MAE、MoCo v3、SimCLR v2等)相比具有相当的性能,并且它能有效地应用于未知的任务和域。

论文链接:https://arxiv.org/pdf/2202.03052.pdf
代码链接:https://github.com/ofa-sys/ofa
创新
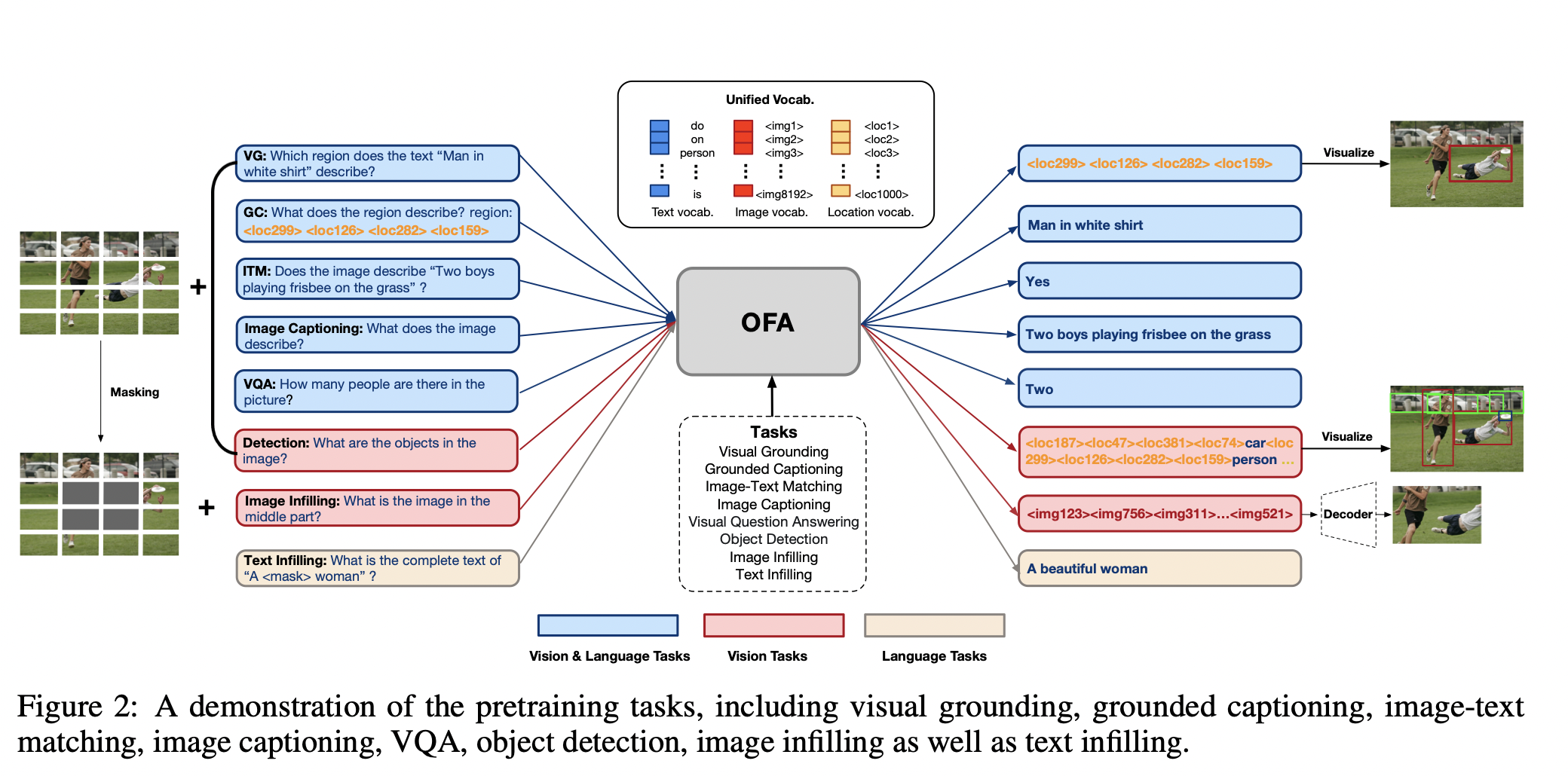
- 本文提出了OFA模型以实现任务无关、模态无关的学习框架,该模型通过sequence-to-sequence学习框架将多模态、单模态任务融合到一起,并能够支撑图像生成、视觉检索、VQA、图像描述、图像分类、语言建模等多个任务。
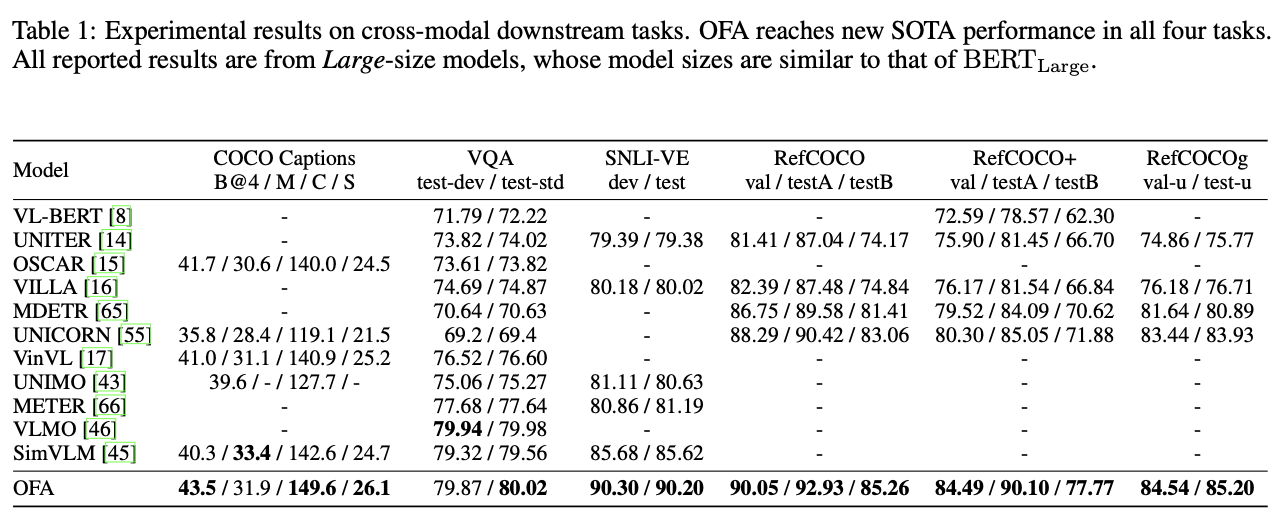
- OFA在一系列多模态任务上都达到了新水平,包括图像描述(COCO CIDEr: 149.6)、文本到图像的生成(COCO FID: 10.5)、VQA (test-std acc: 80.02), SNLI-VE(测试acc。 90.20),referring expression comprehension(RefCOCO / RefCOCO+ / RefCOCOg test acc。: 92.93 / 90.10 / 85.20)。
- 证明了OFA在零样本学习设定下同样具有领先的效果。此外,OFA还可以处理out-of-distribution数据及未知任务。
实验
Referring expression comprehension
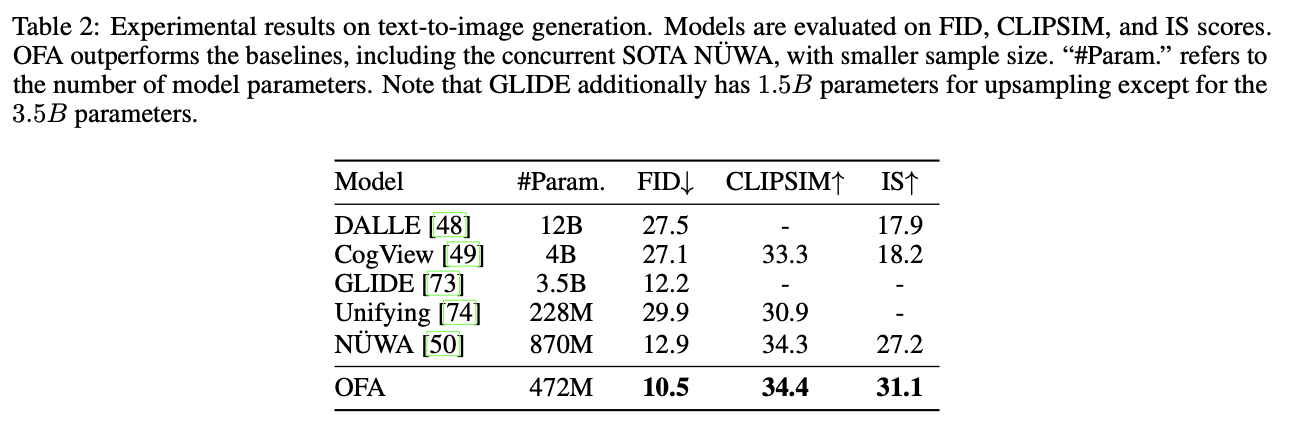
图像生成

VQA

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢