
【标题】VRL3: A Data-Driven Framework for Visual Deep Reinforcement Learning
【作者团队】Che Wang, Xufang Luo, Keith Ross, Dongsheng Li
【发表日期】2022.2.17
【论文链接】https://arxiv.org/pdf/2202.10324.pdf
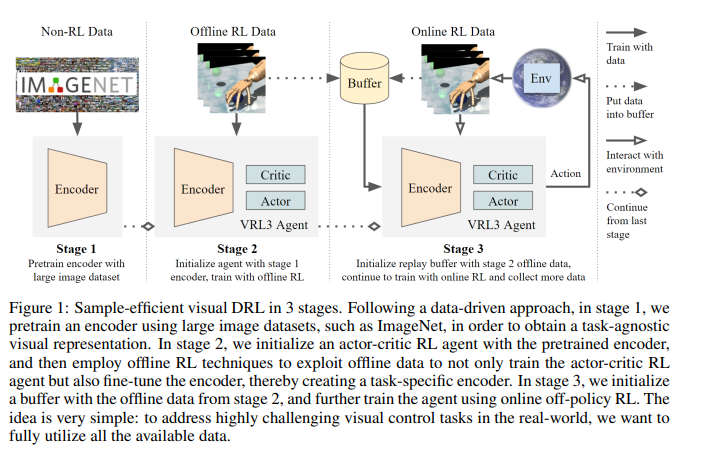
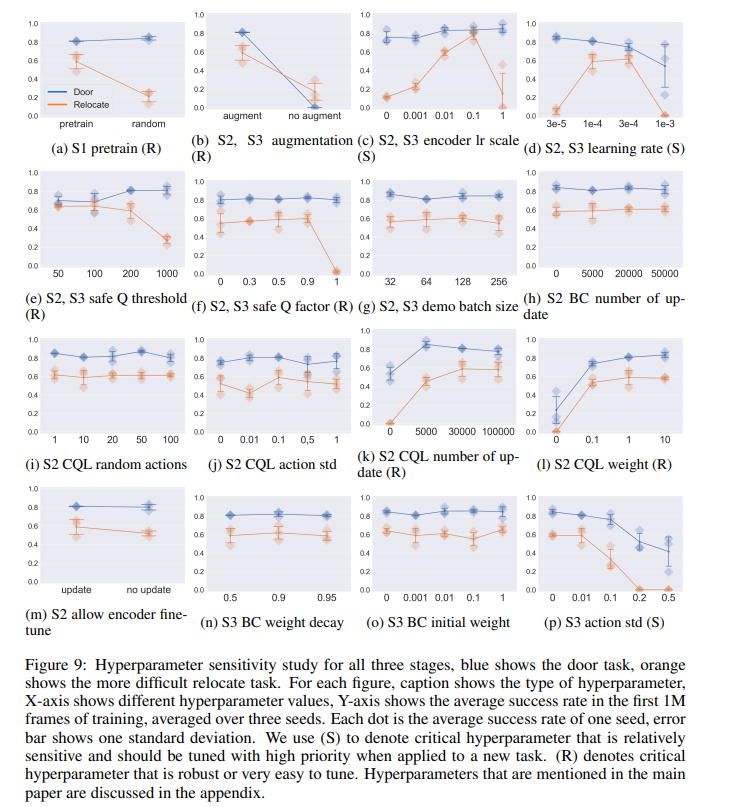
【推荐理由】本文提出了一个简单但功能强大的数据驱动框架,用于解决极具挑战性的视觉深层强化学习(DRL)任务。其分析了采用数据驱动方法的一些主要障碍,并提出了一套关于数据驱动视觉DRL的设计原则、训练策略和关键见解。该框架分为三个阶段:第一阶段,利用非RL数据集(如ImageNet)学习任务无关的视觉表征;在第二阶段,使用离线RL数据(例如,有限数量的专家演示)将任务不可知表示转换为更强大的任务特定表示;在第三阶段,通过使用在线RL微调智能体。在一组具有稀疏奖励和真实视觉输入的极具挑战性的手部操作任务中,该框架比之前的SOTA方法学习速度快370%-1200%,同时使用了一个小50倍的编码器,充分展示了数据驱动的深度强化学习的潜力。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢