
在 ICCV 2021 上,商汤科技-南洋理工大学联合 AI 研究中心 S-Lab 的研究者提出了分布式无监督表示学习新范式 FedU --- 从分布式无标签的图片数据中,在隐私保护的前提下,进行表示学习。FedU 采用分布式联邦学习的方式,从多个数据源进行无监督表示学习,从而能被进一步用在下游任务上。
论文链接:
FedU 用一个云端服务器联合多个边端设备进行训练,在训练初始时,云端服务器初始化一个编码器 (Encoder) 和一个预测器 (Predictor),并发送给多个边端,初始化边端模型。再次之后,整个训练流程包括四个步骤(参考下图):
1. 本地训练:每个边端采用孪生神经网络使用本地数据进行无监督对比学习。
2. 模型上传:每个边端将训练好的模型上传到云端。
3. 模型融合:云端聚合模型,产生新的模型。
4. 模型更新:云端使用新的模型更新边端的模型。
这四个步骤组成了一回合的训练,FedU 不断迭代这四个步骤,直到完成训练。在这个过程中,我们采用了当时最新的 BYOL[1] 对比学习方法进行本地训练,并设计了云边通信协议和发散感知的网络更新策略。
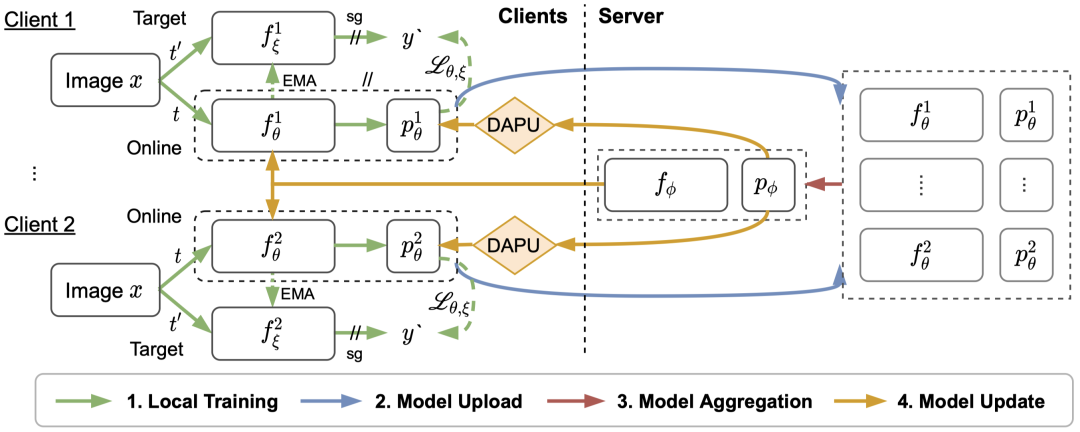
图 1 FedU 训练流程图
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢