
【论文标题】Fine-Tuning can Distort Pretrained Features and Underperform Out-of-Distribution
【作者团队】Ananya Kumar, Aditi Raghunathan, Robbie Jones, Tengyu Ma, Percy Liang
【发表时间】2022/02/21
【机 构】斯坦福
【论文链接】https://arxiv.org/abs/2202.10054v1
【备注】ICLR2022 oral
当把预训练的模型转移到下游任务时,两种流行的方法是完全微调(更新所有的模型参数)和线性探测(只更新最后的线性层)。众所周知,微调会导致更好的分布内(ID)准确率,然而,本文发现,当预训练的特征很好且分布偏移较大时,微调可以达到比线性探测更差的精度,即分布外(OOD)。在10个分布偏移数据集(Breeds-Living17, Breeds-Entity30, DomainNet, CIFAR → STL, CIFAR10.1, FMoW, ImageNetV2, ImageNet-R, ImageNet-A, ImageNet-Sketch)上,微调平均获得比线性探测高2%的ID准确率,但OOD准确率低7%。本文从理论上证明,即使在一个简单的环境中,也会出现ID和OOD准确性之间的权衡。当本文用固定或随机的头初始化时,微调的OOD误差很高,这是因为在微调学习头的同时,神经网络的下层同时发生变化,并扭曲了预训练的特征。本文的分析表明,简单的两步策略先线性探测然后完全微调(LP-FT)可被用作微调的启发式方法,它结合了微调和线性探测的优点。从经验上看,LP-FT在上述数据集上的表现优于微调和线性探测,ID比全微调好1%,OOD比全微调好10%。
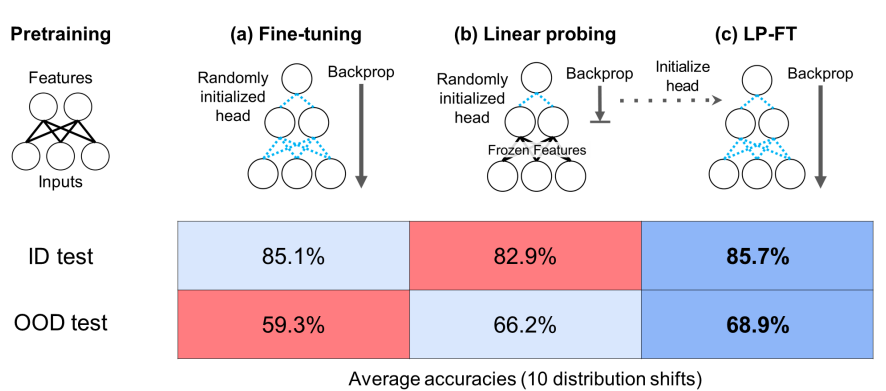
上图显示了如下步骤,给定一个好的特征提取器,添加一个随机初始化的头,将特征映射到输出,本文可以,a:微调所有的模型参数或b:线性探测,冻结特征提取器,只训练头。本文在十个分布转移上进行了实验。当测试实例从微调分布(ID)中取样时,微调表现良好,但在从OOD分布中取样的测试实例上可能表现不佳。c:本文的理论表明,微调会扭曲预训练的特征提取器,导致OOD的准确度很差,但是用线性探测头初始化可以解决这个问题。根据经验,LP-FT在ID和OOD上都能得到更好的准确度。
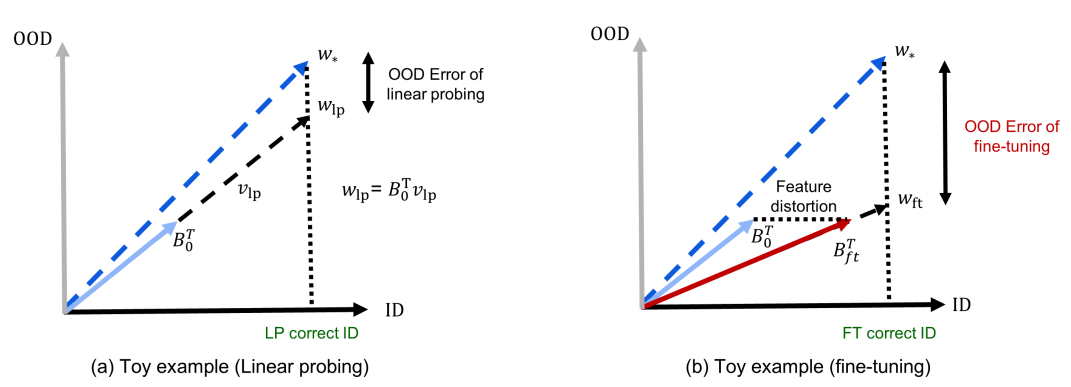
上图展示了一个玩具版本说明了为什么微调会扭曲特征,预训练的特征提取器为B0。线性探测学习wlp,一个预训练的特征提取器的缩放,可以得到正确的ID数据。而微调方法沿着ID数据更新预训练的特征提取器以得到Bft,然后学习这些特征的缩放比例,以得到正确的ID数据。虽然两种方法都能得到正确的ID数据,但微调在垂直于ID数据的方向上会产生很大的误差,因为微调沿ID方向更新B0,但不更新垂直方向,即特征 "失真"。
创新点:
针对目前利用预训练的模型来提高下游性能的趋势,只要可行,通常都会对所有模型参数进行微调,本文从理论和经验上表明保留特征可能对鲁棒性很重要,而像线性探测这样更简单的方法可以提高分布外(OOD)的性能。随着预训练特征质量的提高,微调和线性探测之间的这种OOD差距也在增长,因此随着预训练的创新和规模的不断扩大,本文的结果很可能会获得意义。
对现代深度学习的理论理解仍然有限,特别是预训练和迁移学习的效果。除了本文关于微调的具体结果外,本文的工作还引入了一些工具和想法,以处理在存在多个全局最优的情况下,从特定的初始化中描述轨迹的特性这一主要挑战。此外存在几个开放的问题和扩展,如处理非线性激活、不同的分层学习率和显式正则化的影响。
本文表明LP-FT可以在减轻ID和OOD准确性之间的权衡。LP-FT在其他情况下也是有用的,例如在CLIP中,本文可以用零样本分类器初始化最后一层,然后对整个模型进行微调,就像在同时进行的工作中那样。LP-FT只是利用理论分析的直觉的第一步,本文希望这项工作能激发利用强大的预训练模型的新方法。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢