
2021 年短短一年时间,多种Vision Transformer模型的提出刷新了计算机视觉领域诸多任务的 SOTA。与前期CNN百花齐放式的发展类似,多种 Vision Transformer 模型加剧了新手入坑的难度,为此华为诺亚方舟实验室提出了针对Vision Transformer的综述,该综述目前已被TPAMI录用。

-
论文链接:https://ieeexplore.ieee.org/document/9716741/
-
开源模型:https://github.com/huawei-noah
摘要
2021年之前,卷积神经网络CNN主宰了计算机视觉领域内的诸多主要模型结构,关于它的研究也呈现出多样化的趋势。然而,2021年Vision Transformer的提出异军突起,逐渐展露出全面取代CNN的发展潜力。以谷歌提出的ViT框架为例,Vision Transformer首先将图像进行分割,接着图像块作为一个序列,从而使用纯Transformer模型进行建模以完成图像分类任务,在多个公共数据集上取得了优越的性能。除图像分类之外,目标检测、语义分割、图像处理等多个任务的SOTA性能同样被Vision Transformer模型不断刷新。根据它们的提出时间,本文作者首先整理出如下发展里程碑:
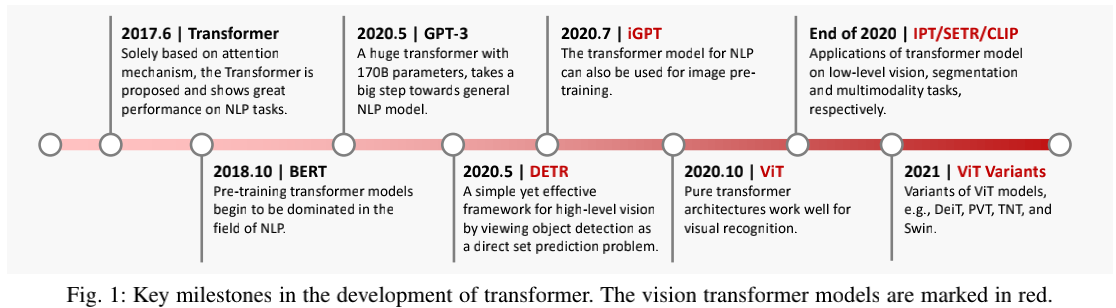
与CNN类似,Vision Transformer的研究同样涵盖了模型架构、损失函数、建模机制等多个方向,这使得Vision Transformer的入门非常困难。因此,本文作者收集了200余篇前沿研究,并根据它们的设计思路和应用场景进行分类,为Vision Transformer提供了详细的机制分析和性能对比,最终提出了若干具有发展潜力的研究方向:
-
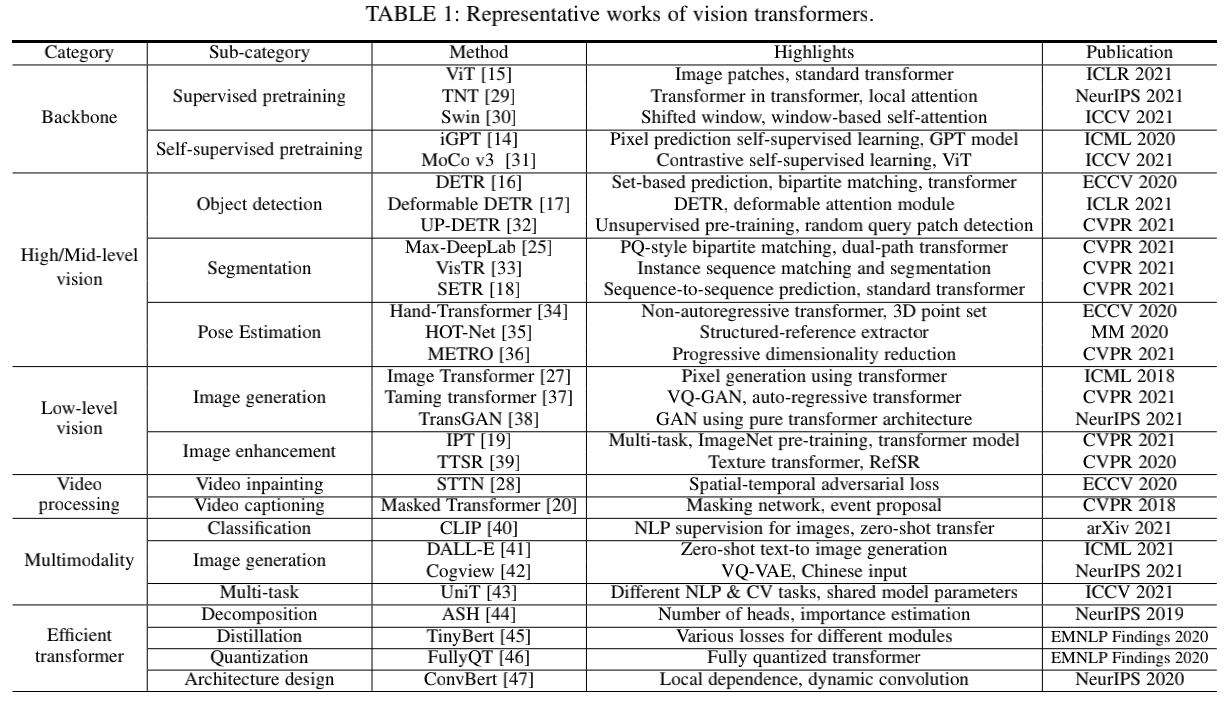
本文对视觉 Transformer 模型进行了系统性的归类,如表 1 所示:骨干网络、高 / 中层视觉、底层视觉、多模态等,并且在每一章中针对任务特点进行详细分析和对比;
-
本文针对高效的视觉 Transformer 进行了详细的分析,尤其是在标准数据集和硬件上进行了精度和速度的评测;
-
本文基于华为的研究、经验,联合了业界知名学者一起进行了深入思考和讨论,给出了几个很有潜力的未来方向,供大家参考。
骨干网络
除层归一化、非线性激活层等CNN常用的模块,Vision Transformer还包括多头自注意力、多层感知机、残差连接、位置编码等特有模块,而正是这些特有模块使得Vision Transformer在多个任务上均超越了CNN。为了提高Vision Transformer的性能,诸多强化模型例如金字塔多头注意力机制、自适应位置编码被纷纷提出,而在这些强化模型中骨干网络的性能提升效果作为明显。本文在下表中对骨干网络的强化模型进行了对比分析,不难发现,相比较于纯CNN或纯Vision Transformer模型,CNN+Vision Transformer才是最佳的骨干网络设计思路。
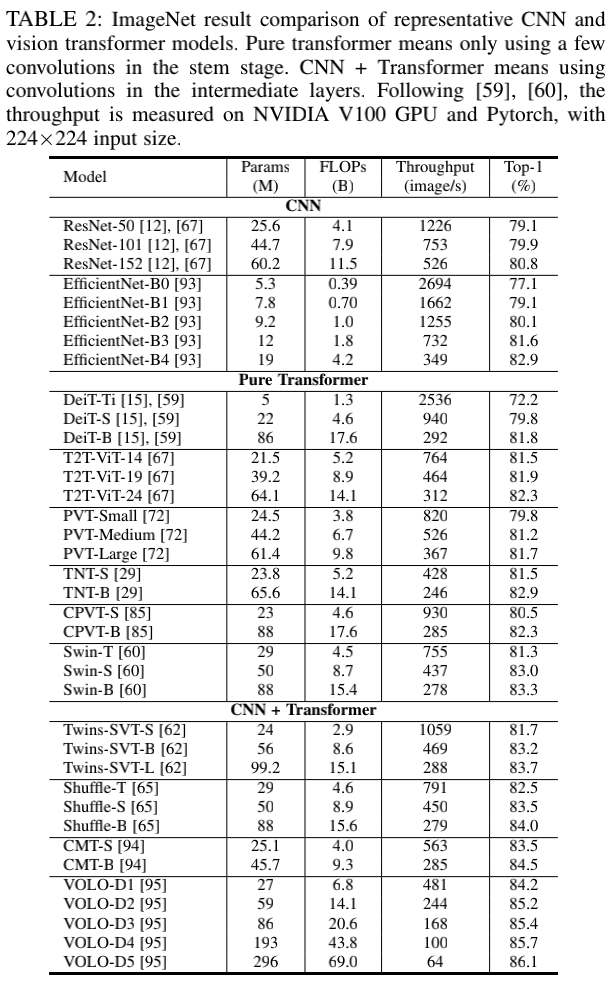 表2 代表性 CNN 和 Transformer 网络在 ImageNet 结果的对比。
表2 代表性 CNN 和 Transformer 网络在 ImageNet 结果的对比。
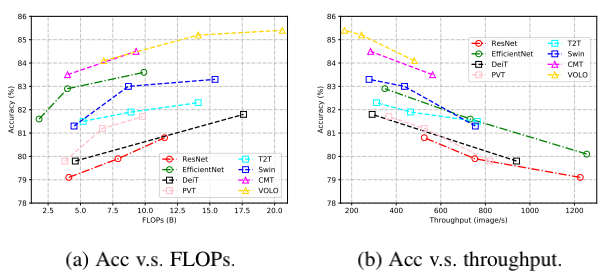
图 2 代表性 CNN 和 Transformer 网络的 FLOPs / 吞吐量对比
目标检测
基于 Transformer 的目标检测方法也引起了广泛的兴趣,这些方法大致可以分为两类:基于 Transformer 的检测集合预测方法和基于 Transformer 骨干网络的检测方法。与基于 CNN 的检测器相比,基于 Transformer 的方法在准确性和运行速度方面都表现出了强大的性能。表 3 展示了在 COCO 数据集上基于 Transformer 的不同目标检测器的性能。
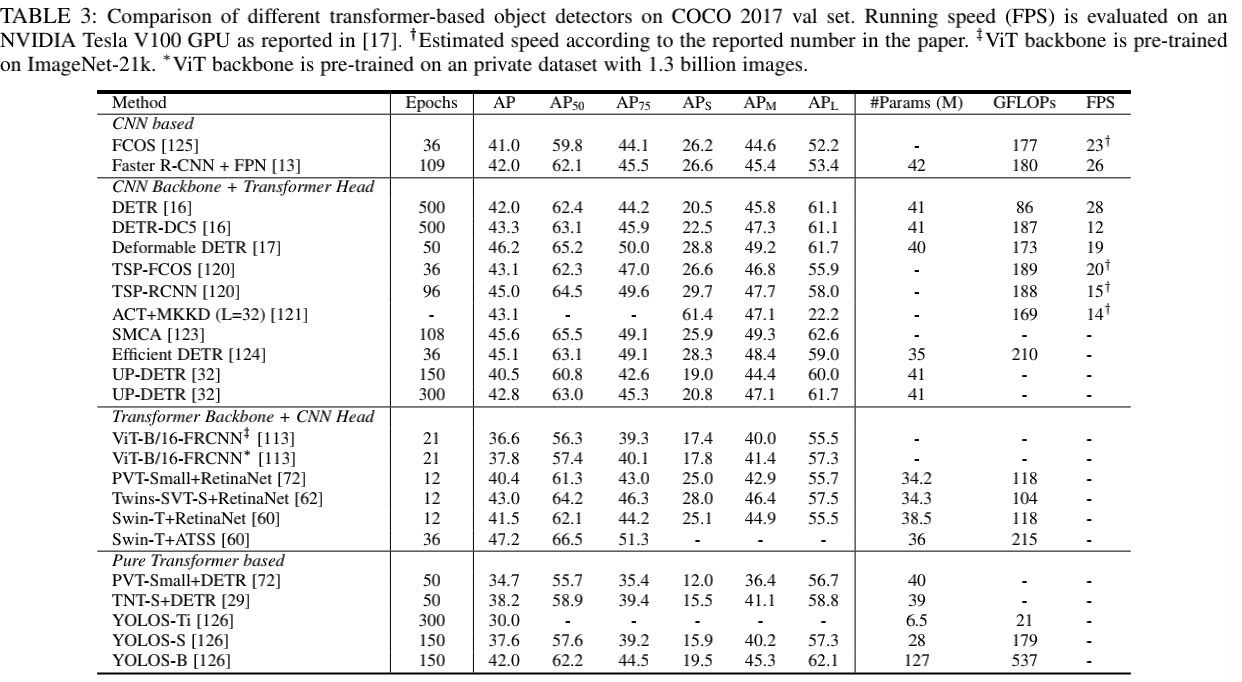
表 3 基于 Transformer 的目标检测器在 COCO2017 上的结果对比
底层视觉
图像超分辨率和图像生成等底层视觉同样是计算机视觉领域的一个重要问题,目前也有一些团队专心于研究如何将 Transformer 应用于底层视觉中来。图 3 和图 4 展示了在底层视觉中使用 Transformer 的方式。在图像处理任务中,首先将图像编码为一系列 token,Transformer 编码器使用该序列作为输入,进而用 Transformer 解码器生成所需图像。在图像生成任务中,基于 GAN 的模型直接学习解码器生成的 token,通过线性映射输出图像,而基于 Transformer 的模型训练自编码器学习图像的码本,并使用自回归 Transformer 模型预测编码的 token。而一个有意义的未来研究方向是为不同的图像处理任务设计合适的网络架构。
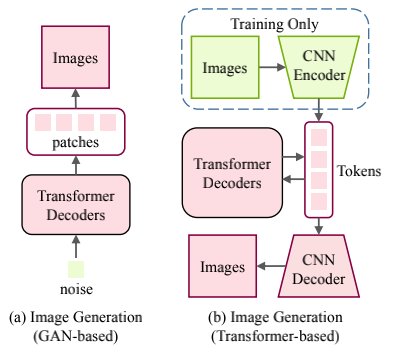
图 3 基于 Transformer 的图像生成
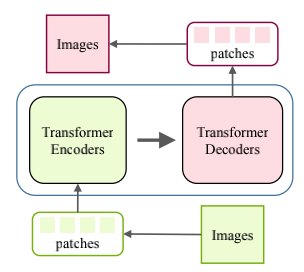
图 4 基于 Transformer 的图像处理
多模态
许多研究开始热衷于挖掘 Transformer 在处理多模态任务(如视频 - 文本、图像 - 文本和音频 - 文本)的潜力。CLIP 是其中影响力较大的一个工作, 其将自然语言作为监督信号,来学习更有效的图像表示。CLIP 使用大量文本图像对来联合训练文本编码器和图像编码器。CLIP 的文本编码器是一个标准的 Transformer,具有 mask 的自注意力层;对于图像编码器,CLIP 考虑了两种类型的架构:ResNet 和视觉 Transformer。CLIP 在一个新采集的数据集上进行训练,该数据集包含从互联网上收集的 4 亿对图像 - 文本对。CLIP 展示了惊人的零样本分类性能,在 ImageNet-1K 数据集上实现了 76.2% top-1 精度,而无需使用任何 ImageNet 训练标签。总之,基于 transformer 的多模态模型在统一各种模态的数据和任务方面显示出了其架构优势,这表明了 transformer 具备构建一个能够处理大量应用的通用智能代理的潜力。
高效 Transformer
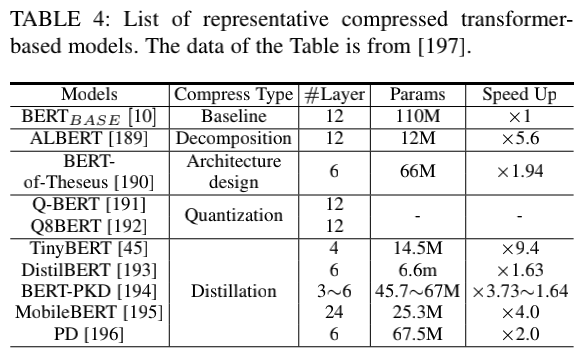
尽管 Transformer 模型在各种任务中取得了成功,但它们对内存和计算资源的高要求阻碍了它们在端侧设备(如手机)上的部署。文章还回顾了为高效部署而对 Transformer 模型进行压缩和加速的研究,这包括网络剪枝、低秩分解、知识蒸馏、网络量化和紧凑结构设计。表 4 列出了一些压缩 Transformer 模型的代表性工作,这些工作采用不同的方法来识别 Transformer 模型中的冗余。
未来展望
作为一篇综述论文,对所探究的领域未来方向的牵引也是非常重要的。本文的最后,也为大家提供了几个有潜力并且很重要的方向:
-
业界流行有各种类型的神经网络,如 CNN、RNN 和 Transformer。在 CV 领域,CNN 曾经是主流选择,但现在 Transformer 变得越来越流行。从现有的观察来看,CNN 在小数据集上表现良好,而 Transformer 在大数据集上表现更好。而在视觉任务中,究竟是使用 CNN 还是 Transformer,或者兼二者之所长,是一个值得探究的问题。
-
大多数现有的视觉 Transformer 模型设计为只处理一项任务,而许多 NLP 模型,如 GPT-3,已经演示了 Transformer 如何在一个模型中处理多项任务。CV 领域的 IPT 能够处理多个底层视觉任务,例如超分辨率、图像去雨和去噪。将所有视觉任务甚至其他任务统一到一个 Transformer(即一个大统一模型)中是一个令人兴奋的课题。
-
另一个方向是开发高效的视觉 Transformer,即如何让 Transformer 具有更高精度和更低资源消耗。
-
Transformer 能否通过更简单的计算范式和大量数据训练获得令人满意的结果?
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢