
摘要
自何凯明老师提出视觉自监督学习新范式——掩蔽自编码器MAE依赖,基于Masked Image Modeling的自监督学习表征算法得到了诸多关注。这一类表征学习算法的主要思路是对图像进行分块和随机遮掩操作,然后要求自编码器对掩码区域做预测。预测的目标可以是Token,也可以是图像的被遮掩部分。通过MIM这一类方法进行预训练,自编码器可以学习到通用的表征,从而在下游任务中取得良好的泛化性能。本文认为,近期两个代表性工作BEiT和MAE,没有充分挖掘编码器的潜力,限制了预训练学习的表征质量。

论文链接:https://arxiv.org/abs/2202.03026
创新
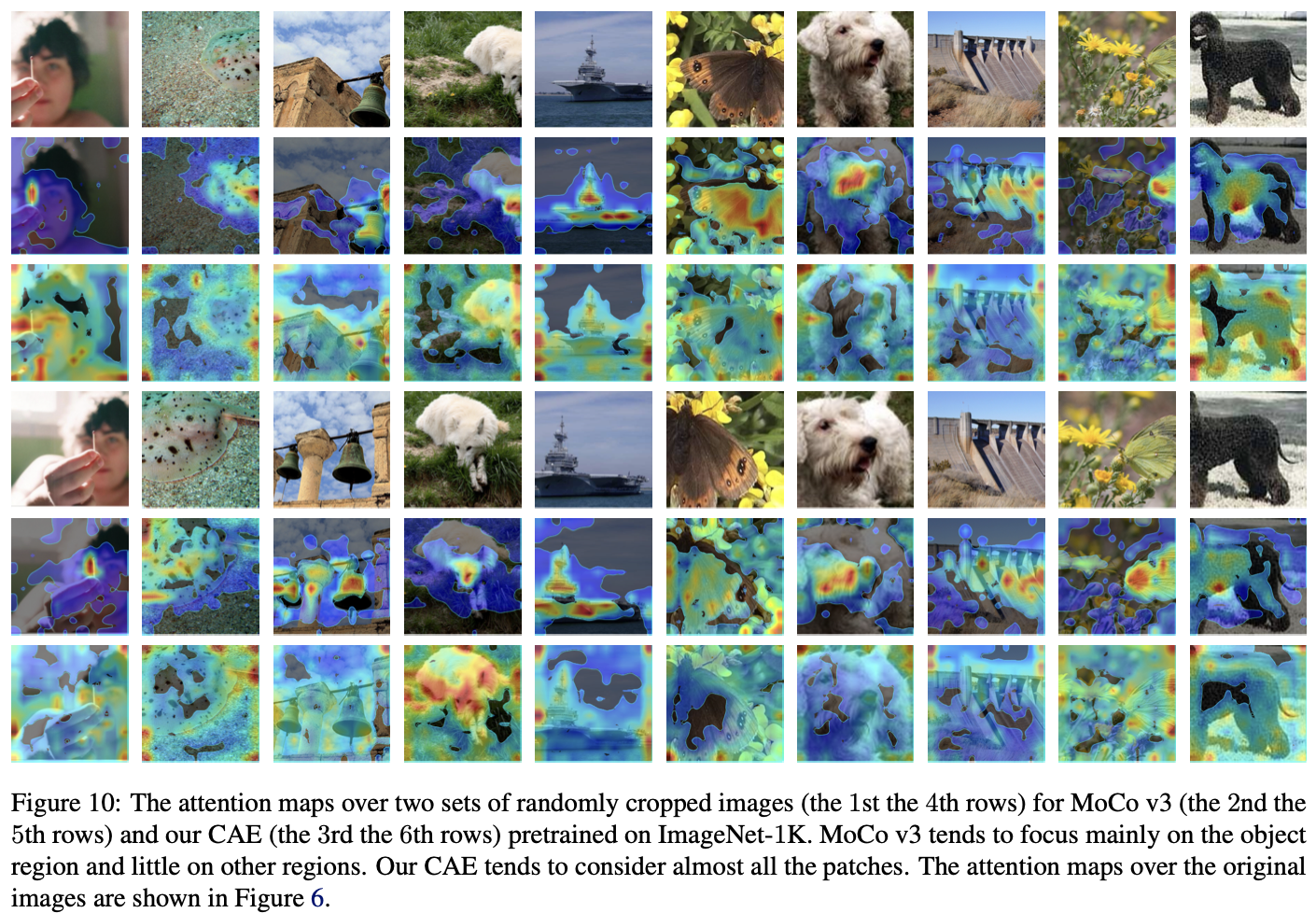
为充分挖掘编码器的特征建模能力,作者提出了Context Autoencoder,即CAE。其主要动机是为编码器将表征学习、前置任务(pretext task)实现任务分离。因此,在预训练阶段,编码器只需专注于特征学习,由解码器解决前置任务,通过二者的分工最大化编码器表征能力。
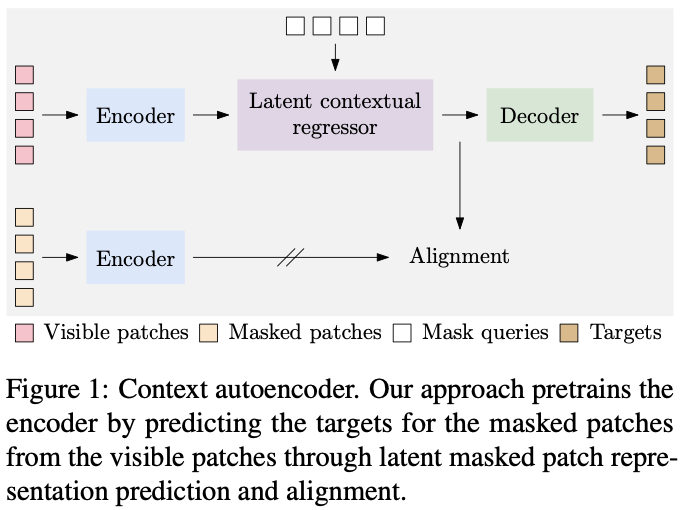
CAE主要包含四个部分:
- 编码器:是一个Vision Transformer模型,负责学习图像表征
- 潜在上下文回归其(latent contextual regressor):预测图像掩蔽部分的特征
- 解码器:根据预测特征生成相应输出
- 潜在约束:约束latent contextual regressor 的输出和编码器的输出在同一空间
实验结果
本文使用ViT-small和ViT-base在 ImageNet-1K 上进行实验,输入图像的分辨率224*224,每张图被分成14*14的patch,每个patch的大小为16*16。
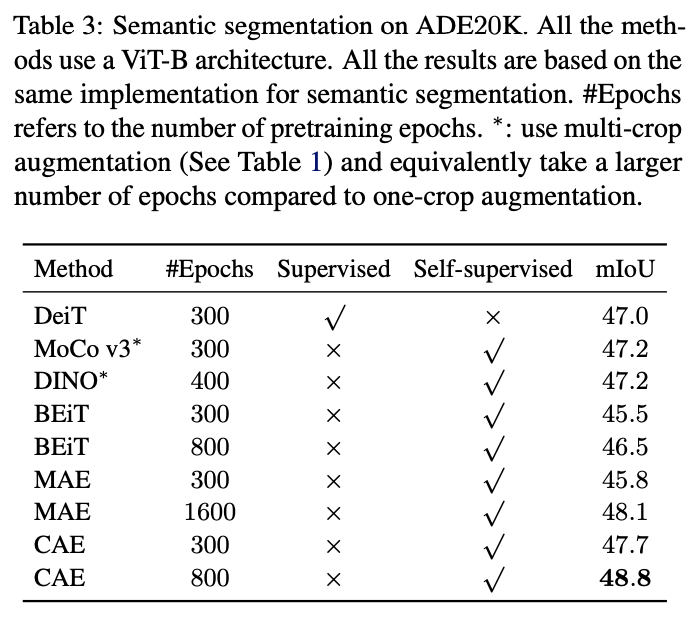
语义分割
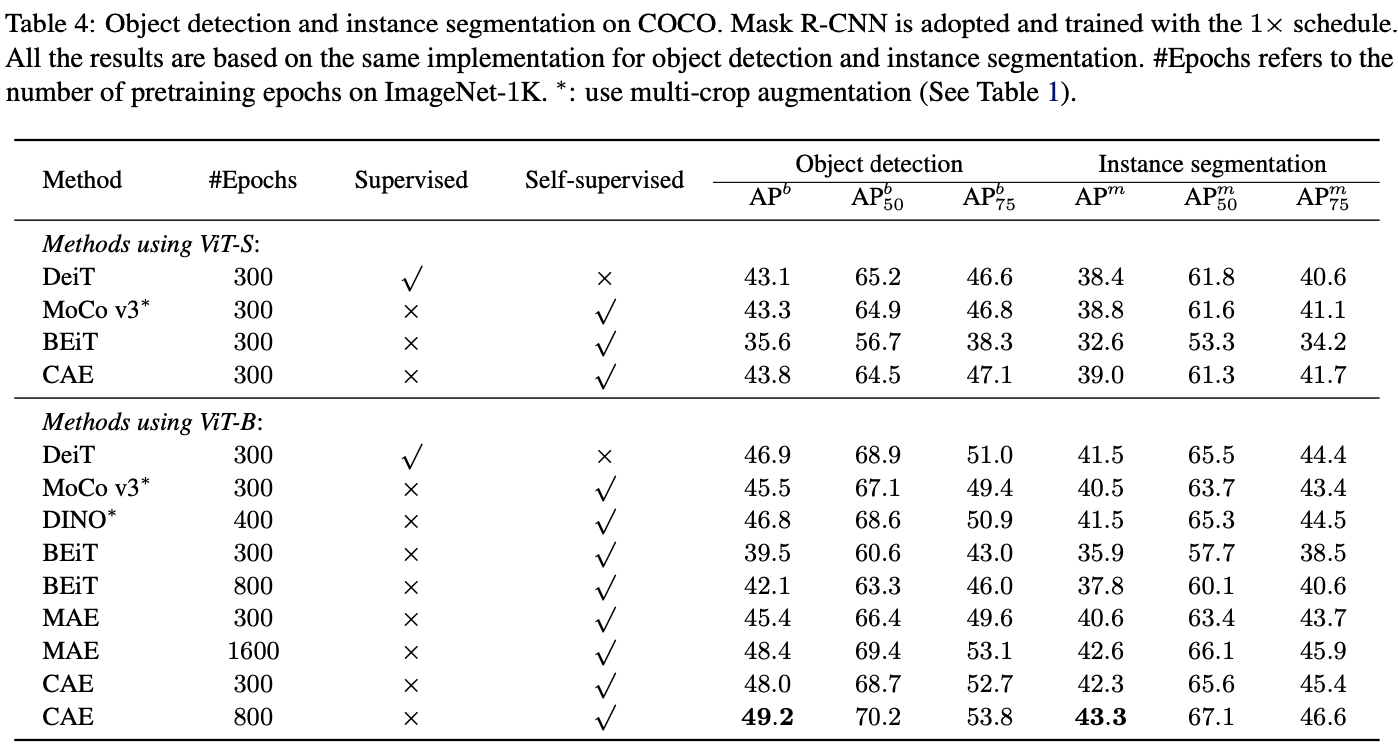
物体检测
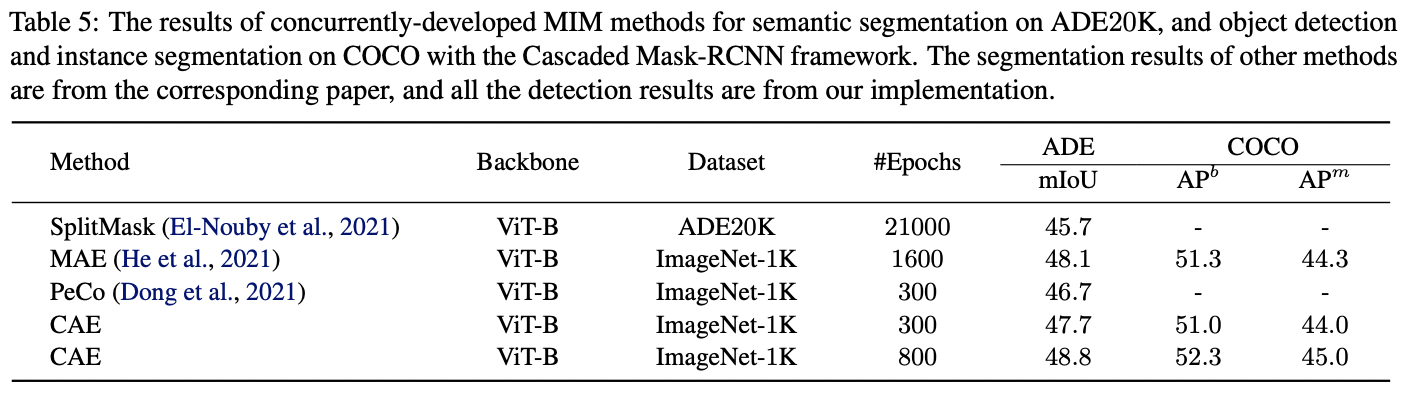
实例分割
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢