
【论文标题】From Unstructured Text to Causal Knowledge Graphs: A Transformer-Based Approach
【作者团队】Scott Friedman, Ian Magnusson, Vasanth Sarathy, Sonja Schmer-Galunder
【发表时间】2022/02/21
【机 构】Smart Information Flow Technologies. (SIFT)
【论文链接】https://arxiv.org/abs/2202.11768v1
定性因果关系表达了世界上离散或连续的相互作用的方向、依赖性、时间约束和单调性约束。在日常或学术语言中,我们可以表达数量之间的相互作用,例如睡眠会减少压力,离散事件或实体之间的相互作用,例如一种蛋白质会抑制另一种蛋白质的转录,或者意向性或功能性因素之间的相互作用,例如医院的病人祈祷以减轻他们的痛苦。提取和表示这些不同的因果关系对于在从科学发现到社会科学等领域运作的认知系统来说至关重要。本文提出了一个基于Transformer的NLP架构,它联合提取知识图谱,包括用语言描述的变量或因素,这些变量上的定性因果关系,限制这些因果关系的限定词和量级,以及在大型本体中定位每个提取节点的词义。我们并不声称我们的基于Transformer的架构本身就是一个认知系统;然而,我们提供了证据,证明它在现实世界的领域中准确地提取知识图谱,并证明其产生的知识图谱对于进行基于图谱的推理的认知系统的实用性。我们展示了这种方法,包括在两个用例中的结果,处理来自学术出版物、新闻文章和社会媒体的文本输入。
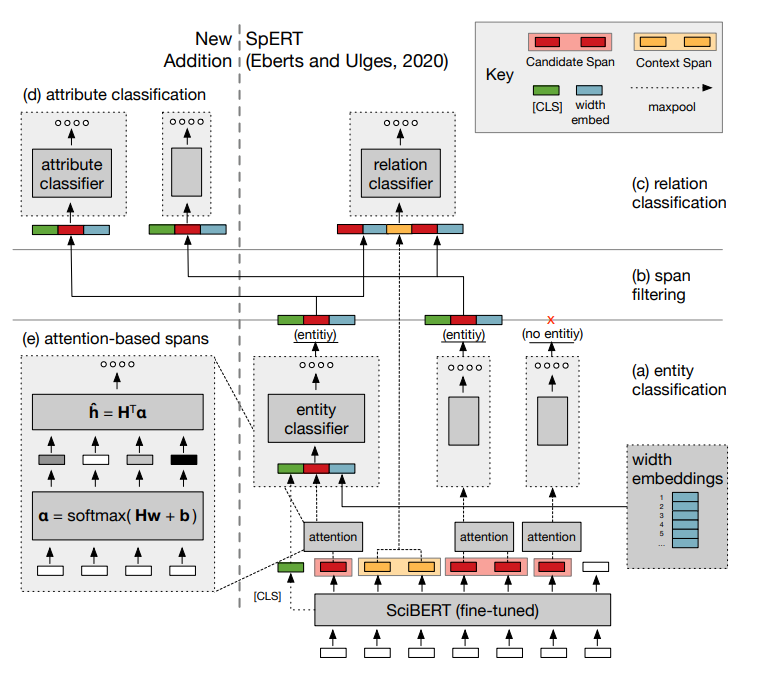
结合预训练模型的架构:上图展示了基于SpEAR Transformer的属性分类流程,其扩展了SpERT组件,对识别的实体span和span的基于注意力的表示进行多标签推理。SpEAR模型架构用一个属性分类器和基于注意力的span表示法扩展了SpERT。原有的架构提供了在可能重叠的文本span上联合提取实体和关系的组件。实体、属性和关系分类器的参数,以及BERT语言模型的参数(以其预训练值初始化)都是在我们的数据集上进行端到端的训练。
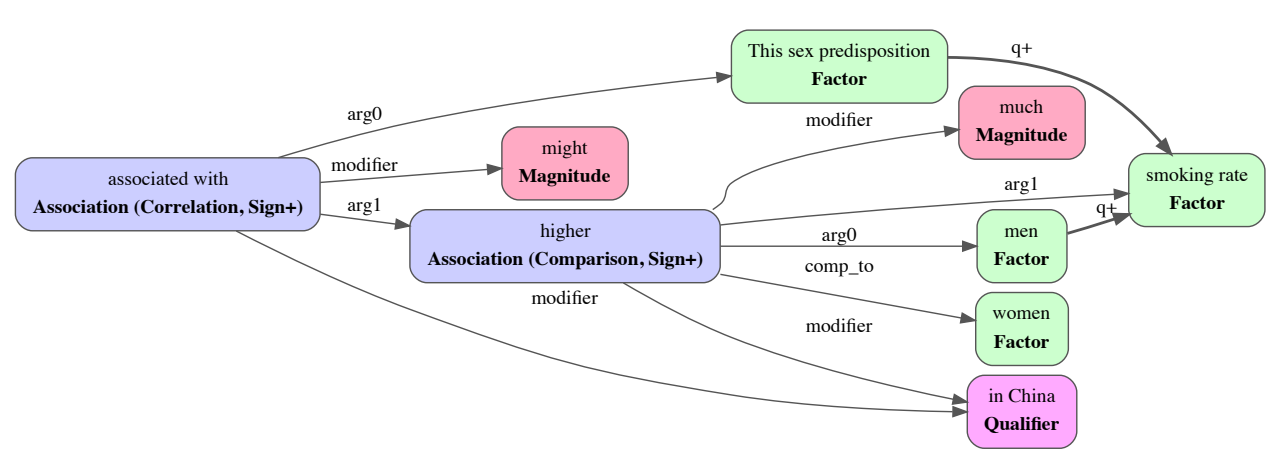
知识图谱:上图展示了SpEAR知识图谱对"这种性别倾向可能与中国男性的吸烟率远高于女性有关"(“This sex predisposition might be associated with the much higher smoking rate in men than in women in China.”)的输出,包括相关性、与质的增加的比较、量级和位置限定词。
现有的符号语义分析器从具有明确关系知识表征的文本中提取科学主张的过程中,多数依靠基于规则的引擎,通过手工调整,提供更多的定制和可解释性,这样做的代价是需要NLP专家来维护和适应新领域。其他NLP方法使用机器学习从科学文本中提取特征,没有明确推断因果图中元素之间的关系或术语的本体论基础。
相比之下,本文的方法是利用基于Transformer的模型SpERT来提取因果知识图,由此产生的知识图是以本体论为基础的,并支持基于图的推理,不过这些知识图并不像一些SOTA符号解析器那样富有表现力。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢