视觉语言预训练提高了许多视觉语言任务的性能。但是,现有的多数预训练方法依赖目标检测器(object detectors)提取基于物体的视觉特征,以此学习细粒度的视觉和语言对齐,例如物体(object)级别。然而,这种方法存在识别视觉概念有限、图像编码上下文信息丢失和计算效率低下的问题。
在本文中,字节跳动人工智能实验室提出了 X-VLM,以统一的方法学习多粒度的视觉和语言对齐,不依赖目标检测方法且不局限于学习图片级别或物体级别的对齐。该方法在广泛的视觉语言任务上获得了最先进的结果,例如:图像文本检索 (image-text retrieval)、视觉问答(VQA)、视觉推理(NLVR)、视觉定位 (visual grounding)、图片描述生成(image captioning)。
论文标题:
Multi-Grained Vision Language Pre-Training: Aligning Texts with Visual Concepts
论文链接:
代码链接:
https://github.com/zengyan-97/X-VLM
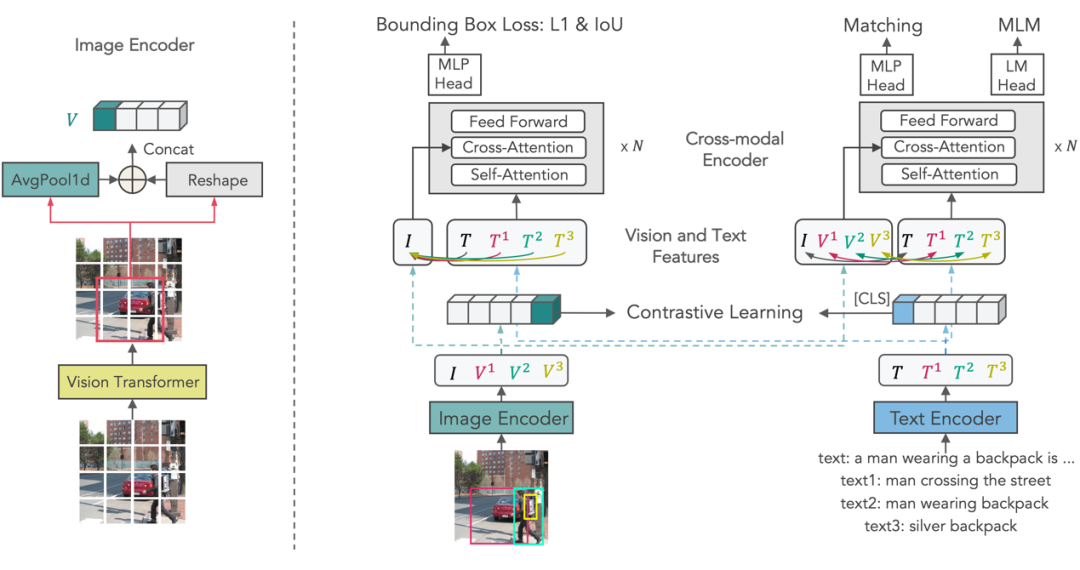
X-VLM框架
X-VLM 由一个图像编码器,一个文本编码器,一个跨模态编码器组成。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢