
作者:Zhangyin Feng, Duyu Tang, Cong Zhou, 等
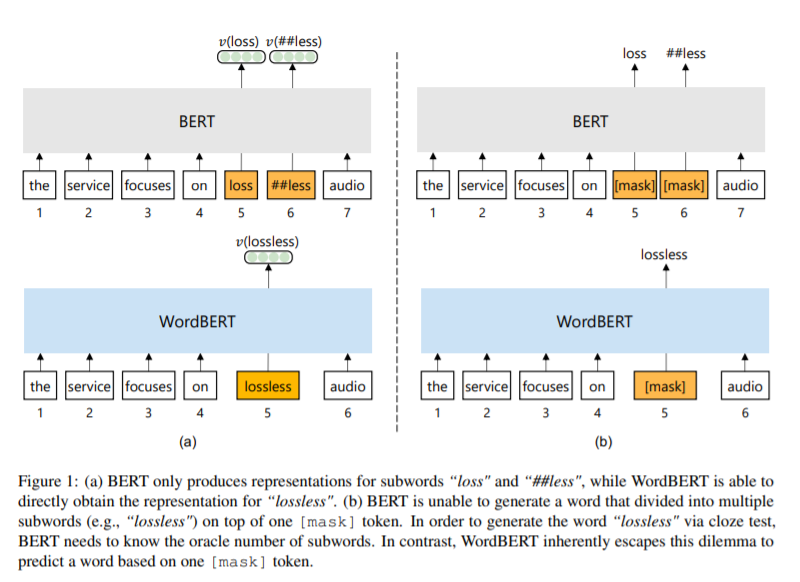
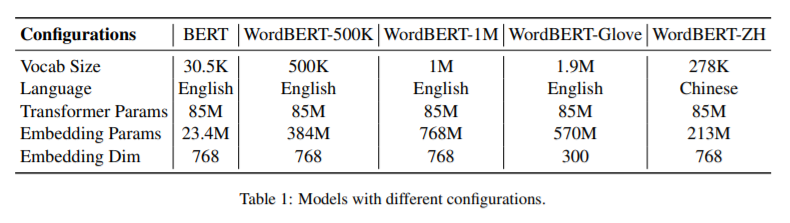
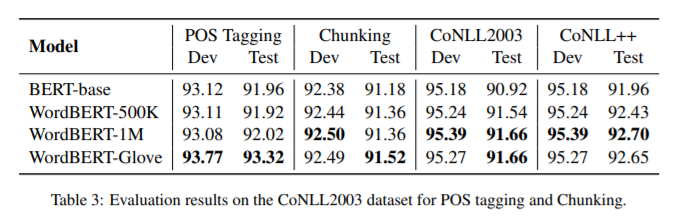
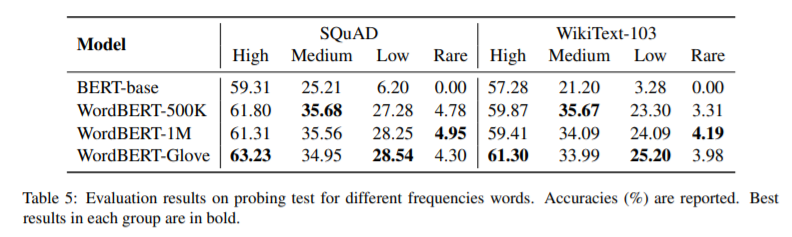
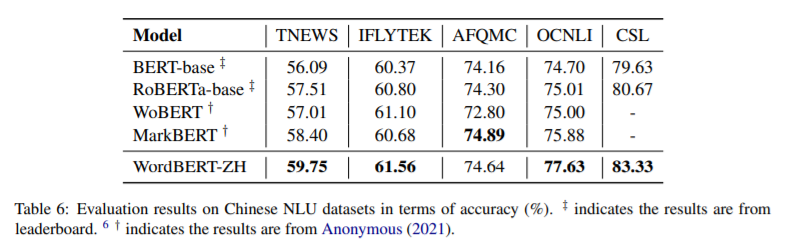
简介:本文研究基于单词的词汇表上训练BERT风格的预训练模型。标准的BERT采用基于单词的标记化,这可能会将一个词分成两个或多个词条(例如,将“无损”转换为“丢失”和“更少”)。这在以下情况下会带来不便:(1)获得一个被分成多个单词的单词的上下文向量的最佳方法是什么?(2) 如何通过完形填空测试预测一个单词而不事先知道词条的数量?在这项工作中,作者探索了在词汇表而不是词条上开发BERT风格的预训练模型的可能性。作者称这种词级的BERT模型为WordBERT。作者使用不同的词汇表大小、初始化配置和语言来训练模型。结果表明,与基于标准词条的BERT相比,WordBERT在完形填空测试和机器阅读理解方面有显著提高。在许多其他自然语言理解任务中,包括词性标注、组块和NER,WordBERT的表现始终优于BERT。模型分析表明,WordBERT比BERT的主要优势在于对低频词和稀有词的理解。此外,由于pipeline 与语言无关,作者对WordBERT进行了中文训练,并在五个自然语言理解数据集上获得了显著的收益。最后,对推理速度的分析表明,WordBERT在自然语言理解任务中的时间开销与BERT相当。
论文下载:https://arxiv.org/pdf/2202.12142
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢