
【论文标题】Survey of Hallucination in Natural Language Generation
【作者团队】Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Yejin Bang, Andrea Madotto, Pascale Fung
【发表时间】2022/02/22
【机 构】港科大
【论文链接】https://arxiv.org/abs/2202.03629v2
近年来,由于深度学习技术的发展,如基于Transformer的预训练语言模型,自然语言生成(NLG)得到了指数级的改善。这种进步使得自然语言生成更加流畅和连贯,自然而然地带动了下游任务的发展,如抽象概括、对话生成和数据到文本生成。然而这种生成包括幻觉文本,这使得文本生成的性能在许多现实世界的场景中不能满足用户的期望。目前为了解决这个问题,已有研究对各种任务中都提出了对幻觉的评估和缓解方法。本文对NLG的幻觉问题的研究进展和挑战做了一个广泛的概述,该综述首先对度量标准、缓解方法和未来方向进行了总体概述,随后在一大批下游任务中针对幻觉的具体研究进展,包括抽象总结、对话生成、生成性问题回答、数据到文本生成和机器翻译。
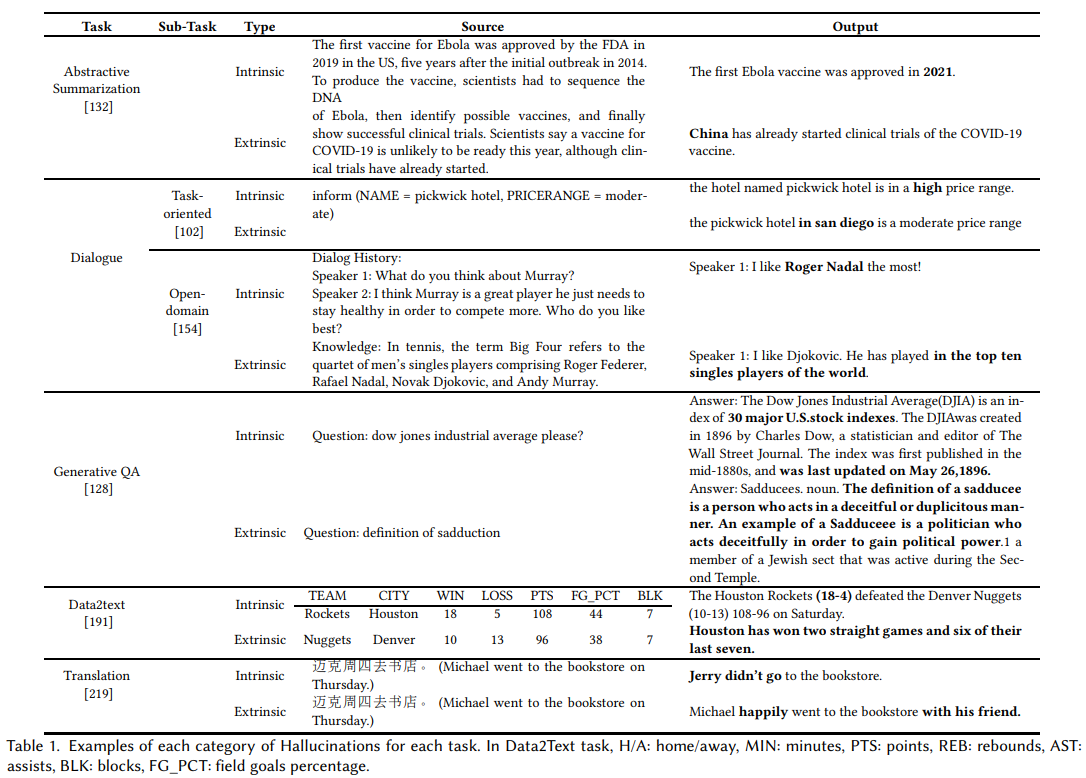
本任务中的幻觉的定义如下:
内在(Intrinsic)幻觉:生成的反应与对话历史或外部知识句子相矛盾;
外在(Extrinsic)幻觉:生成的反应难以与对话历史或外部知识句子进行验证。
上图所示展示了内在幻觉的例子,本文可以验证,输出与他们的输入相矛盾。当输入是一个 "中等 "的价格范围时,模型错误地生成了一个 "高 "价格范围的句子。Roger Federer "和 "Rafael Nadal "这两个名字的混淆导致输出结果为 "“Roger Nadal"。另一方面,具有外在幻觉的反应不可能用给定的输入来验证。换句话说,"pickwick hotel "可能是 "“in san diego",Djokovic可能 "in the top ten singles players of the world",但是,本文没有足够的信息来核实。
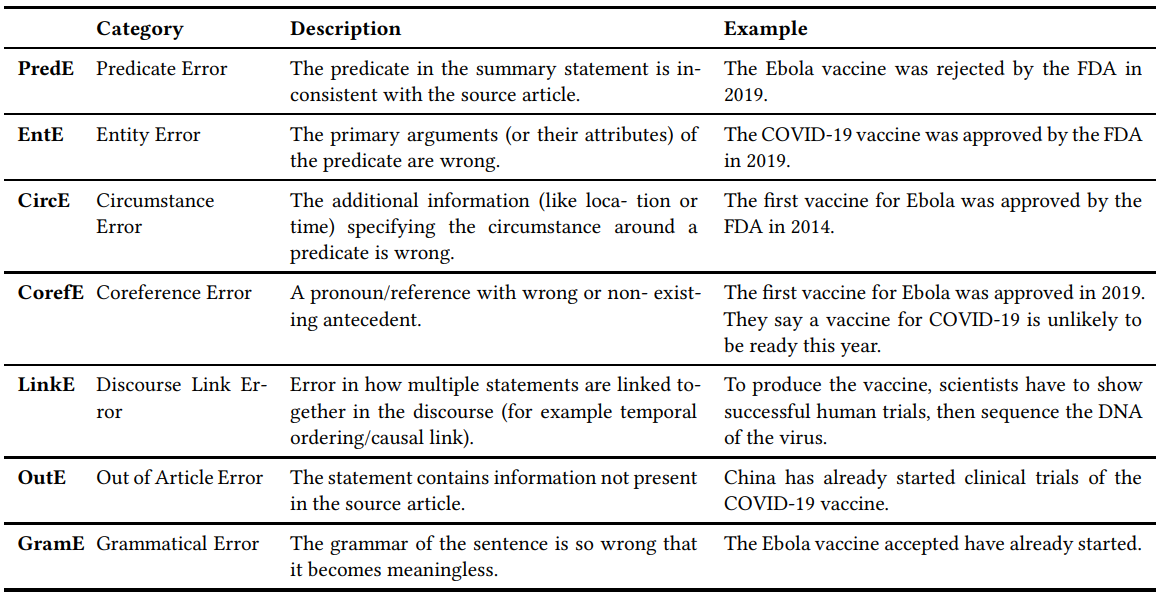
上图展示了幻觉出现的事实错误的类型。例子的原始文本为 "The first vaccine for Ebola was approved by the FDA in 2019 in the US, five years aer the initial outbreak in 2014. To produce the vaccine, scientists had to sequence the DNA of Ebola, then identify possible vaccines, and finally show successful clinical trials. Scientists say a vaccine for COVID-19 is unlikely to be ready this year, although clinical trials have already started."。
举个例子,“The Ebola vaccine was rejected by the FDA in 2019” 为一个内在幻觉因为他与“The first vaccine for Ebola was approved by the FDA in 2019 in the US”矛盾。“China has already started clinical trials of the COVID-19 vaccine.”是一个外在幻觉。
总结:
本综述首次对NLG中的幻觉问题进行了全面的概述。作者总结了现有的评估指标、缓解方法以及未来研究的剩余挑战。幻觉是基于神经的自然语言生成的一个伪命题,由于它们看起来很流畅,因此会对用户产生误导,因而受到关注。在某些场景和任务中,幻觉会造成伤害。本文调查了造成幻觉的各种因素,从嘈杂的数据、错误的参数化知识、不正确的注意力机制、不恰当的训练策略到推理暴露偏差等。本文表明存在两类幻觉,即内在的幻觉和外在的幻觉,它们需要用不同的缓解策略来对待。幻觉在摘要总结和NMT中相对容易检测到,与源中的证据相对应。对于对话系统来说,平衡对话反应的多样性和一致性是很重要的。GQA中的幻觉对其性能是不利的,但是在这个领域,对缓解方法的研究仍然是非常初步的。对于数据到文本的生成,幻觉产生于输入和输出格式之间的差异。大多数缓解NMT中的幻觉的方法要么是试图减少数据集的噪音,要么是缓解曝光偏差。在识别和减轻NLG中的幻觉方面仍有很多挑战,本文希望这一领域的研究能从这次调查中受益。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢