
作者:Yong Dai, Linyang Li, Cong Zhou,等
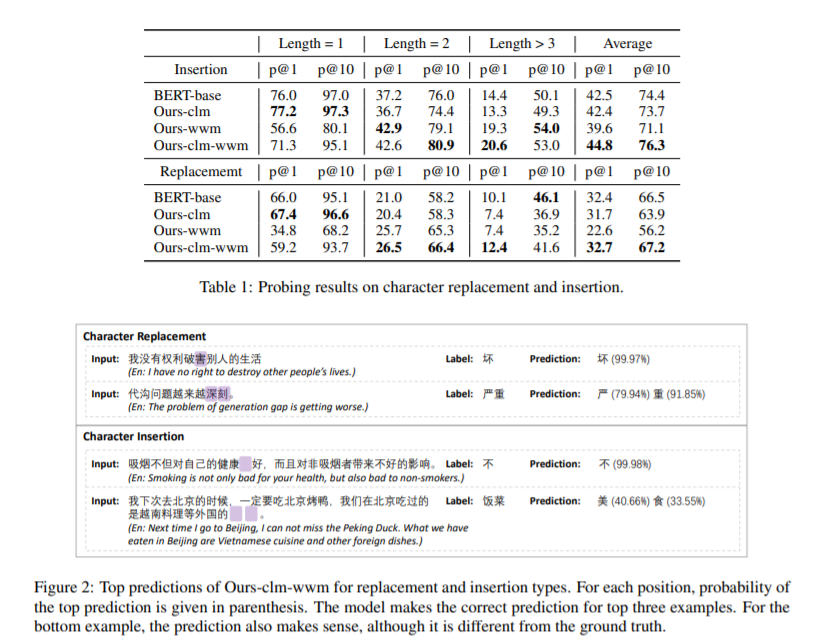
简介:本文根据汉语特点进行预训练模型遮罩的策略研究。一个单词对应的所有子词的遮罩(Whole word masking ,简称:WWM) ,已促成更好的英文BERT 模型。然而,对于中文来说,没有子词,因为每个记号都是一个原子字符。一个词在汉语中的意义不同,一个词是由多个字符组成的组成单元。这种差异促使作者研究 WWM 是否会为中文 BERT 带来更好的上下文理解能力。为此,作者引入了两个与语法纠错相关的探测任务,并要求预训练模型以掩码语言建模的方式修改或插入标记。作者构建了一个数据集,包括 10,448 个句子中 19,075 个标记的标签。作者分别使用标准字符级掩码 (CLM)、WWM 、以及 CLM 与 WWM 的组合训练三个中文 BERT 模型。作者的主要发现如下:首先,当需要插入或替换一个字符时,使用 CLM 训练的模型表现最好。其次,当需要处理多个字符时,WWM 是提高性能的关键。最后,在对句子级下游任务进行微调时,使用不同遮罩策略训练的模型表现相当。

论文下载:https://arxiv.org/pdf/2203.00286.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢