
本文提出PointCLIP:第一个将 CLIP 应用于点云识别的工作,它将2D预训练的知识迁移到3D领域,可在没有任何 3D 训练的情况下对点云进行跨模态零样本识别,代码即将开源!

单位:上海AI Lab, 北大, 港中文
代码:https://github.com/ZrrSkywalker/PointCLIP
论文下载链接:https://arxiv.org/abs/2112.02413
最近,通过对比视觉-语言预训练 (CLIP) 进行的零样本和小样本学习在 2D 视觉识别方面表现出鼓舞人心的表现,该方法学习在开放词汇设置中将图像与其对应的文本进行匹配。然而,通过 2D 中的大规模图像-文本对预训练的 CLIP 是否可以推广到 3D 识别,仍有待探索。
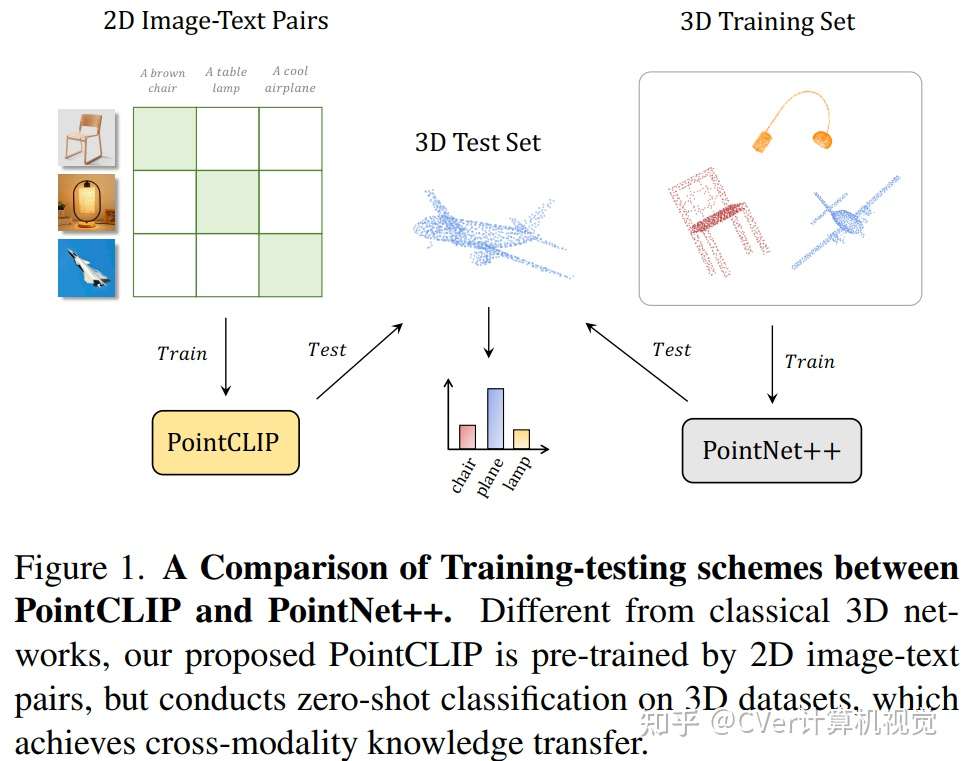
在本文中,我们通过提出 PointCLIP 来确定这种设置是可行的,它在 CLIP 编码的点云和 3D 类别文本之间进行对齐。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢