
【标题】A Survey on Offline Reinforcement Learning: Taxonomy, Review, and Open Problems
【作者团队】Rafael Figueiredo Prudencio, Marcos R. O. A. Maximo, Esther Luna Colombini
【发表日期】2022.3.2
【论文链接】https://arxiv.org/pdf/2203.01387.pdf
【推荐理由】随着深度学习的广泛采用,强化学习(RL)的受欢迎程度显著提高,并扩展到以前难以解决的问题,例如通过像素观察玩复杂游戏、与人类保持对话以及控制机器人代理。然而,由于与环境交互的高成本和危险性,仍有许多领域是RL无法访问的。离线RL是一种仅从先前收集的交互的静态数据集学习的范例,使得从大型和多样化的培训数据集中提取策略成为可能。有效的离线RL算法比在线RL有更广泛的应用范围,尤其适合教育、医疗和机器人等现实世界的应用。本文提出了一个统一的分类法来对离线RL方法进行分类。此外,本文还全面综述了该领域最新的算法突破,并回顾了现有基准的特性和缺点。最后,对开放性问题提出了自己的观点,并对这个快速发展的领域提出了未来的研究方向。
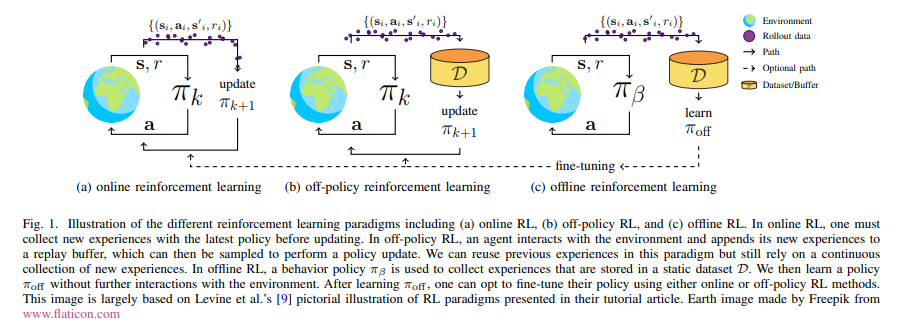
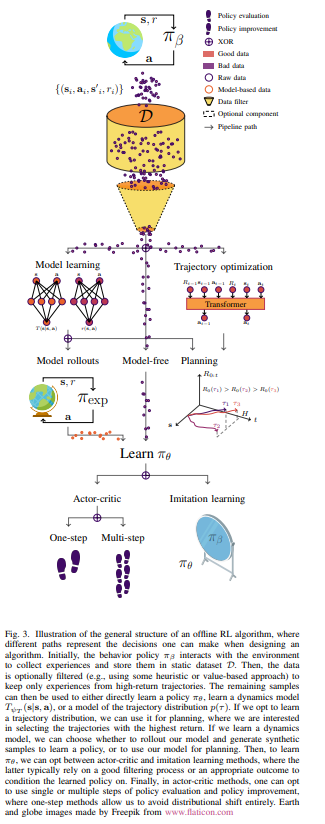
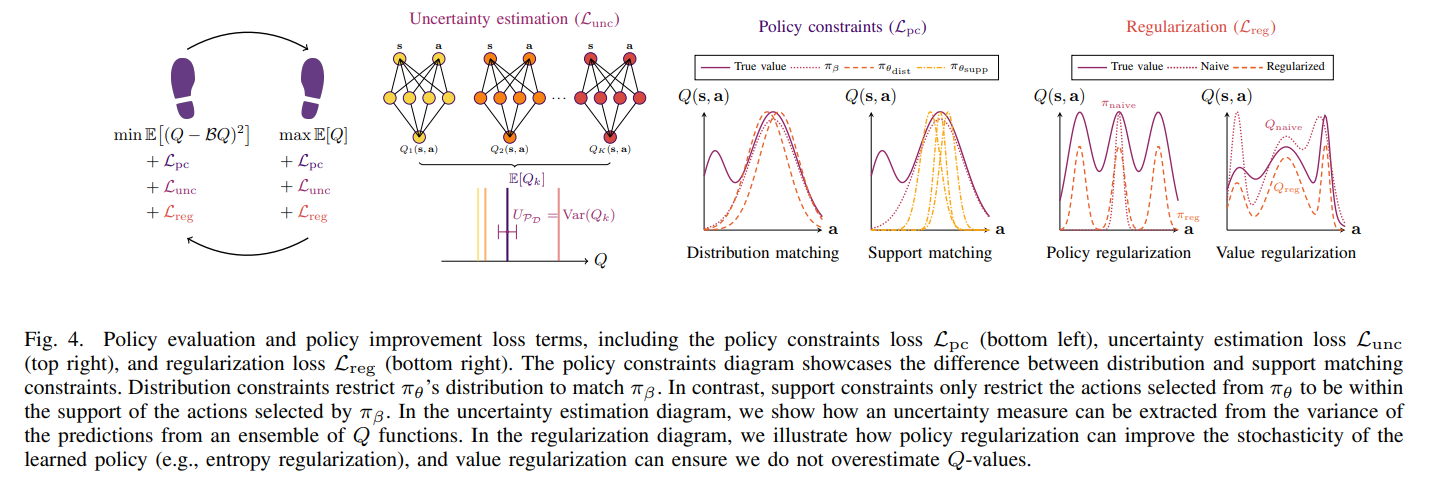
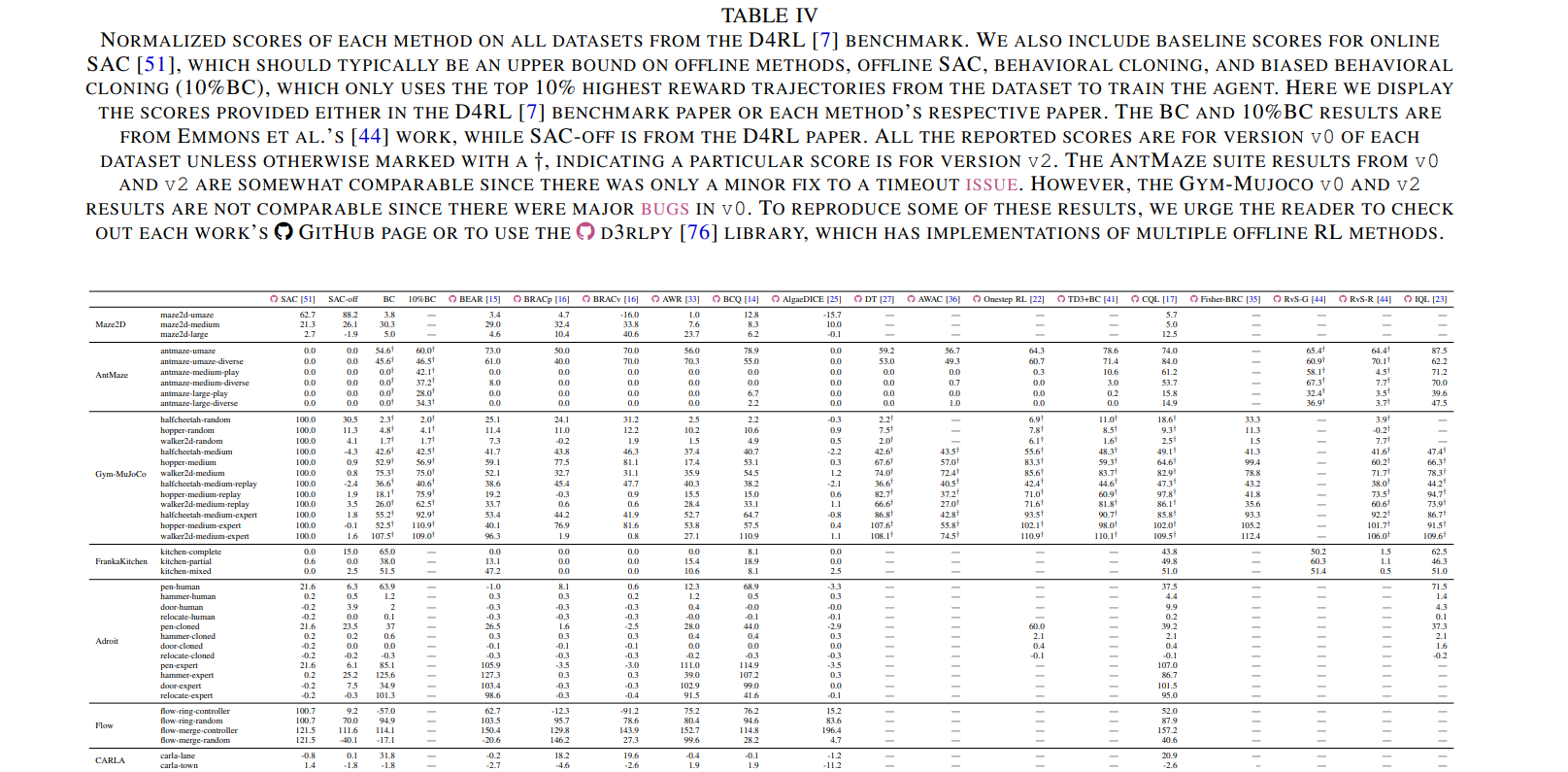
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢