
摘要
近年来,图像修复(image inpainting)取得了重大突破。然而,当图像中的纹理和结构信息出现损坏时,现有研究仍无法进行有效修复。由于卷积神经网络 (CNN) 的有限感受野,一些特定的方法在恢复常规纹理时会丢失整体结构。另一方面,尽管基于注意力机制的模型可以通过长期依赖恢复图像结构,但它们受到大图像尺寸推理所需的计算资源限制。为了解决这些问题,本文作者建议利用额外的结构恢复器来逐步促进图像修复,所提出的模型在低分辨率草图空间中使用强大的Transformer模型来恢复整体图像结构。

paper:https://arxiv.org/abs/2203.00867
code:https://github.com/DQiaole/ZITS_inpainting
动机
图像修复,即填补图像中被遮掩的像素表观,一直是一个热门的挑战性研究。这一研究在目标消除(object removal)、照片复原(photo restoration)、图像编辑(image editing)等应用场景有着广泛的应用,而这些应用要求修复后的图像具有连续的上下文信息和视觉可接受的结构信息。

近年来,随着CNN与GAN等深度结构的发展,图像修复领域取得了较大的突破。然而,现有方法仍受限于下列问题:
- 有限感受野,即便是空洞卷积也无法修复严重缺失的图像;
- 缺失整体结构,如图1底部所示,消除坐在椅子上的人并填补椅子像素仍非常困难;
- 严重的计算负担;
- 遮掩区域缺乏位置信息,即模型不知道遮掩区域内部的结构信息;
为解决这些问题,已有研究提出了多阶段(multi-stage)或多模型(multi-model)的设计思路,但没有工作考虑显示地考量了位置信息(position information)。
基于上述动机,本文作者提出用Transformer模型学习一个正则化的灰度张量空间,从而得到更好的整体结构修复能力。进一步地,作者提出了掩模位置编码机制(masking positional encoding)以提升上述Transformer模型的泛化能力,并证实辅助信息可以直接添加至预训练模型中以提升Transformer模型的修复精度。
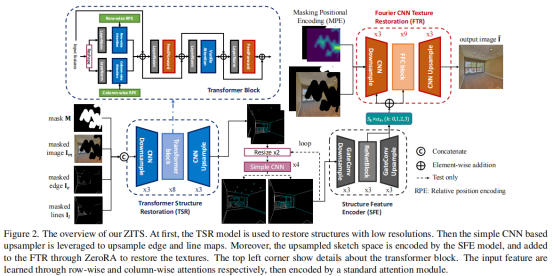
方法
本文提出的模型主要包括五个成分:Transformer Structure Restoration(TSR)、Simple CNN、Structure Feature Encoder(SFE)、Fourier CNN Texture Restoration(FTR)、Masking Positional Encoding(MPE)。
- Transformer Structure Restoration(TSR):Transformer结构修复模块
该模块的主题结构如图2的左上部分所示,首先使用3个卷积层进行多种输入图像的下采样和映射,接着按特征空间尺寸为每个特征点添加一个可学习的位置编码(position embedding),接着使用relative position encoding模块进行全局结构的建模。

- Simple CNN
为了更好地捕获全局结构,作者提出需要将生成的边缘、线条上采样至任意尺度且不造成明显的表观退化,然而,如图3所示,已有方法均会造成一定的表观退化。因此,本文训练一个简单的CNN模型实现上述操作。
- Fourier CNN Texture Restoration(FTR)
为了恢复图像的结构信息,本文采用已有的Fourier卷积模块进行特征修复。Fourier卷积模块中的关键模块是快速傅里叶卷积层,它包含两个支路:局部支路使用常规的卷积操作,全局支路先进行快速傅里叶变换再进行卷积操作。
- Structure Feature Encoder(SFE)
为了对任意尺度的边缘、线条进行特征映射,本文使用一个自编码器模型。该模型包括编码器(3层下采样卷积)、中间模块(3个包含空洞卷积的残差模块)、解码器(3层上采样卷积),中间模块、解码器的多个中间特征同时作为输出:
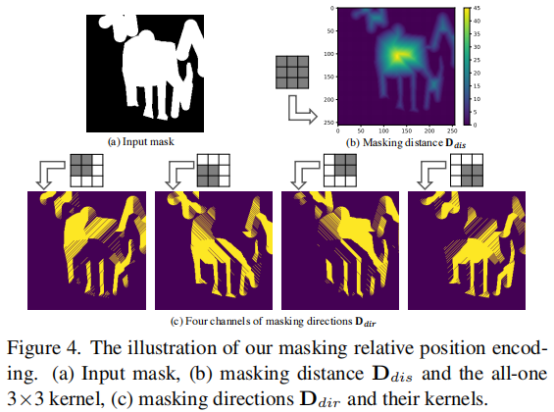
- Masking Positional Encoding(MPE)
本文提出两个观点,对于未遮掩像素,卷积层的padding操作不会影响其表观,但会对遮掩像素的表观造成较大影响。因此,本文作者进一步提出了掩蔽位置编码机制。
实验
在Places2数据集及本文提出的Indoor数据集上,作者分别进行了定量对比和视觉效果对比。
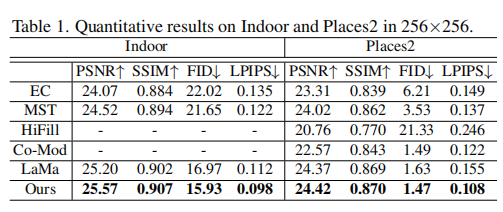
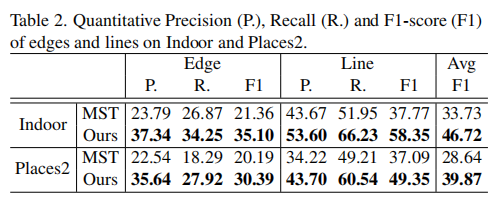
从上表可以看出,本文提出的方法在PSNR、SSIM、FID、LPIPS多个指标上均取得了SOTA的性能。同样地,本文方法在视觉效果上同样取得了一流的性能。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢