标题:港科大、国际数字经济研究院、中科院、清华等|Vision-Language Intelligence: Tasks, Representation Learning, and Large Models(视觉语言智能综述:任务、表示学习和大模型)
作者:Feng Li, Hao Zhang, Lei Zhang等
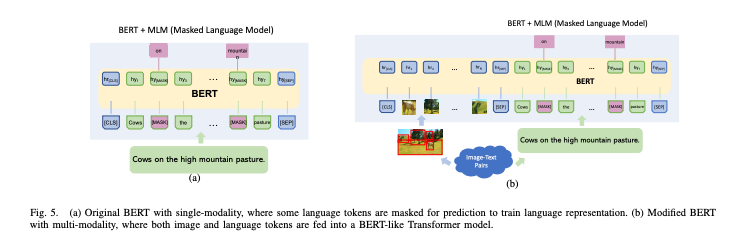
简介:本文提供了一个全面的时间视角下的视觉语言智能综述。这项综述的灵感来自于这两个领域的计算机视觉和自然语言处理显著进展,以及最近从单一模态处理转变为多模态处理模态理解趋势。作者总结了发展该领域分为三个时间段,即特定任务的方法,视觉语言预训练 (VLP) 方法和更大的模型由大规模弱标记数据授权。作者先取一些以常见的 VL 任务为例介绍开发特定于任务的方法。然后作者专注于 VLP 方法和全面审查模型结构的关键组成部分和训练方法。之后,作者展示了最近的工作利用大规模原始图像文本数据来学习语言对齐,在零样本或少样本上更好地概括的视觉表示学习任务。最后,作者讨论了一些潜在的未来趋势模式合作、统一表示和知识整合。作者相信这篇评论会面向 AI 和 ML 的研究人员和从业者有所帮助,尤其是那些对计算机视觉和自然语言处理感兴趣。
论文下载:https://arxiv.org/pdf/2203.01922v1.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢