

论文地址:https://arxiv.org/abs/2202.03278
代码地址:https://github.com/xyupeng/ContrastiveCrop
摘要
自SimCLR、MoCo等里程碑式的自监督工作发表以来,对比学习已经在计算机视觉领域引起了极大的关注和广泛的研究。在诸多下游任务上,对比学习预训练的模型已达到甚至超越有监督预模型的迁移训练结果。自监督对比学习一般均采用孪生网络(Siamese network)的架构,即使用相同的网络参数对不同输入对进行特征提取和对比计算,因此,这一思路不可避免地带来了一个问题——如何选取合适的输入对。
在选择输入的样本对时,已有方法大多在一张图像上进行简单的随机裁剪(random crop),忽略了裁剪块之间的语义信息,而这语义信息在对比学习过程中可能会带来一定的性能影响。为此,本文指出传统随机裁剪可能带来的缺陷,并进一步提出了对比裁剪(ContrastiveCrop)机制。ContrastiveCrop旨在确保大部分正样本对语义一致的前提下,加大样本之间的差异性,从而通过最小化对比损失学习到更泛化的特征。ContrastiveCrop属于即插即用的机制,且理论上适用于任何孪生网络架构。实验表明,在几乎不增加训练内存和计算代价的前提下,ContrastiveCrop能够在若干常用数据集上稳定提升当前主流对比学习方法的性能。

动机
对比学习采用的孪生网络结构一般将来自一张图像的不同视角(view)作为输入对,并通过在特征空间中优化它们的距离以实现相似性度量。因此,其中一个重要的关键问题就是如何设计正样本的选择。已有方法均使用随机裁剪来进行输入视角的采样,例如颜色变换(color distortion)、JIGSAW转换等。尽管随机裁剪可以公平地带来不同输入视角,但它们却无法保证孪生网络能够学习到有效的特征表达(如下图所示)。
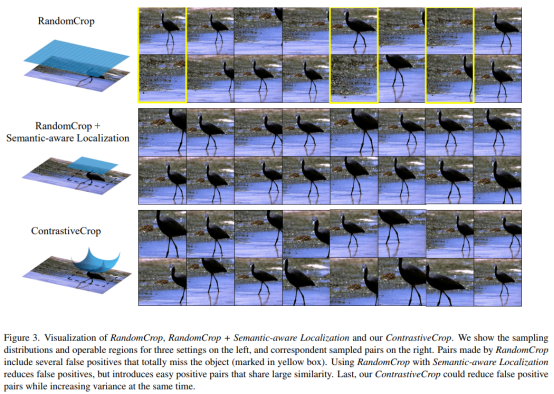
方法
为了解决随机裁剪带来的一系列问题,本文提出的对比裁剪能够利用图像中的语义信息。如下图所示,作何首先对训练过程中的特征图进行了可视化分析。

上图中定位热点的逐渐移动表明在不依赖特定设定的情况下,对比学习模型本身就可以捕捉物体大概的位置信息,但过去的对比学习方法在选取输入视角的时候往往忽略了该信息。为此,作者提出利用深度特征来获取物体边框:
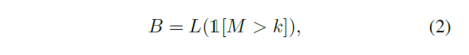
其中M代表特征图,k代表激活阈值,1[]是指示函数,L是计算矩形闭包的函数,B表示物体边框。进一步地,由于物体边框B可能并不准确,作者进一步提出了Semantic-aware Localization:
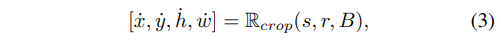
s代表了crop的大小,r是crop的高宽比,Rcrop代表了随机裁剪函数,它返回一个四元组(x, y, h, w),分别定义了crop的中心坐标以及高宽。
Semantic-aware localization很大程度上避免了无效正样本对的裁剪,但也带来了更小的选取范围,使得更可能生成具有较高相似度的样本对。为了解决这个问题,作者提出了“中心压制采样(Center-suppressed Sampling)”,它的核心思想是降低crops集中在图片中心的概率,从而增大采样的方差。将Semantic-aware Localization和Center-suppressed Sampling结合起来,就得到了最终的ContrastiveCrop,具体表示为:
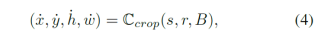
其中Ccrop是代表中心压制采样的函数。整个ContrastiveCrop的流程如下:

实验
本文在CIFAR-10/100, Tiny ImageNet,STL-10和ImageNet数据集上对一些主流对比学习方法(SimCLR, MoCo V1 & V2,BYOL,SimSiam)进行了实验对比:
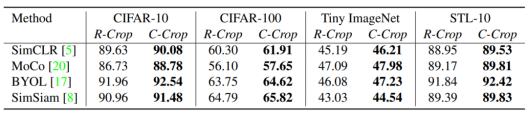
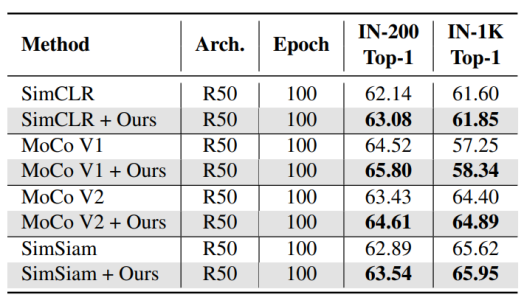
表1对比了RandomCrop和ContrastiveCrop在小规模数据集上的分类性能,表2展示了在ImageNet随机200类(IN-200)以及整个1000类(IN-1K)上的分类准确率。ContrastiveCrop的结果全面高于使用RandomCrop的原始方法。
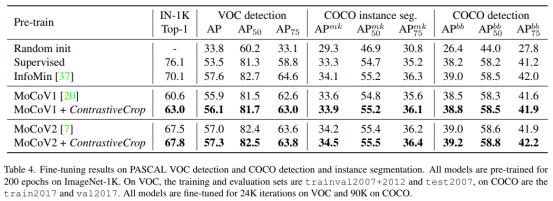
作者同时也在下游目标检测和实例分割任务上验证了ContrastiveCrop优秀的迁移效果:
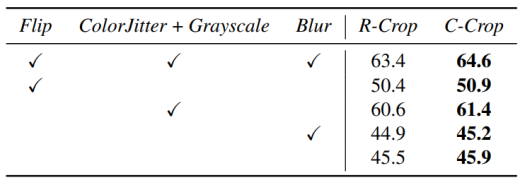
作者还展开了与其他变换结合的消融实验。实验结果表明,单纯使用ContrastiveCrop就可以带来提升,而加上其他所有变换则可以最大程度地发挥ContrastiveCrop的作用:
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢