
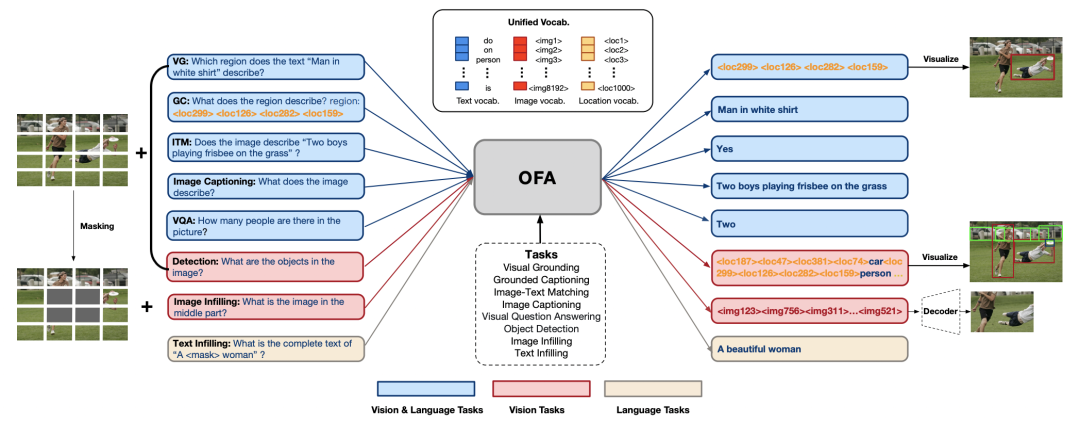
最近阿里达摩院发布了模态、任务、结构统一的模型OFA,将多模态及单模态的理解和生成任务统一到1个简单的Seq2Seq生成式框架中,OFA执行预训练并使用任务指令进行微调,并且没有引入额外的任务特定层进行微调。
具体地说:
统一模态:统一图片、视频、文本的多模态输入形式;
统一结构:采取统一采用Seq2Seq生成式框架;
统一任务:对不同任务人工设计了8种任务指令;
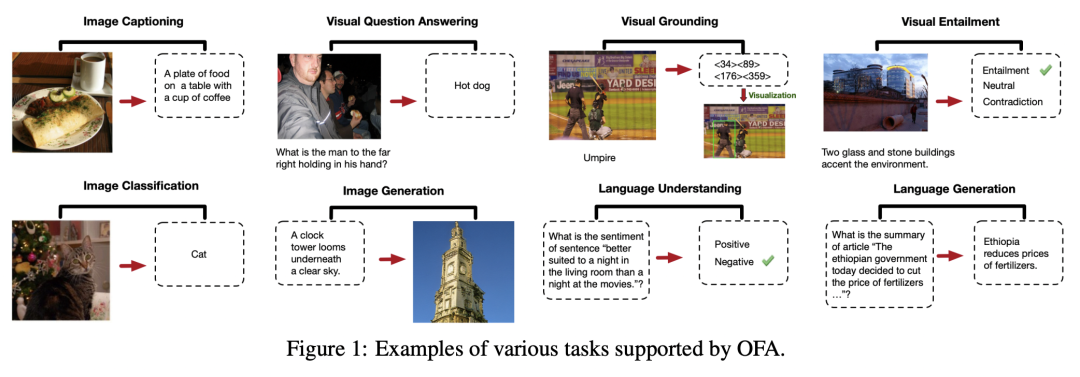
正如上图所说,OFA覆盖的下游任务横跨多模态生成、多模态理解、图片分类、自然语言理解、文本生成等多个场景,在图文描述、图像生成、视觉问答、图文推理、物体定位等多个风格各异的任务上取得SOTA。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢