
一篇AAAI2022的paper《Unified Named Entity Recognition as Word-Word Relation Classification》,刷新了14个中英文数据集的SOTA!
这篇论文整体上也比较简单,主要创新点是利用统一的Word-Pair标记方式建模不同类型的NER任务,并将这一NER统一模型称之为W2NER。
论文链接:
https://arxiv.org/abs/2112.10070
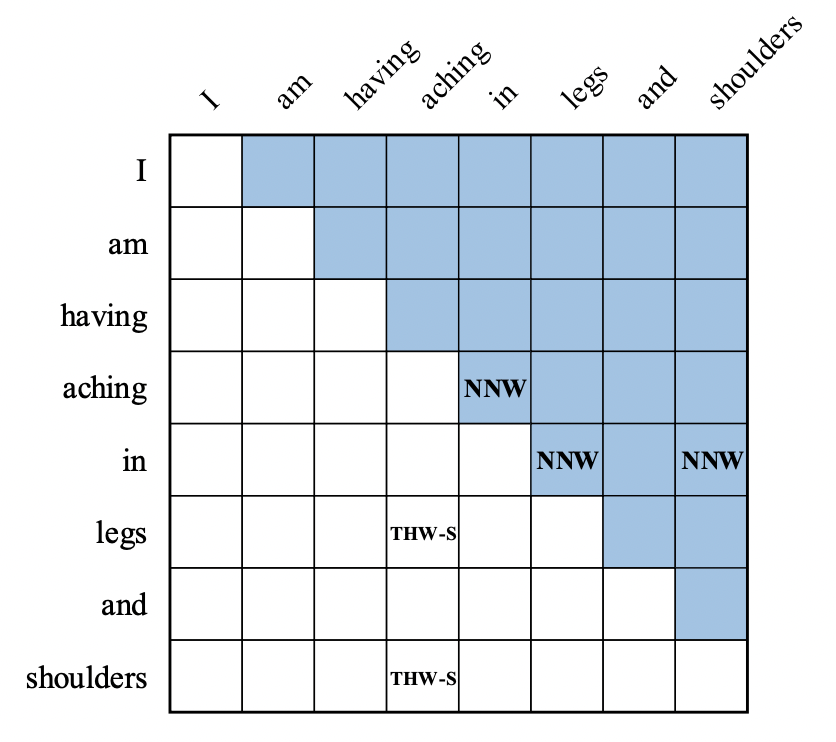
-
NNW(Next-Neighboring-Word):表示当前Word下一个连接接的Word; -
THW(Tail-Head-Word-):实体的tail-Word到head-Word的连接,并附带实体的label信息。
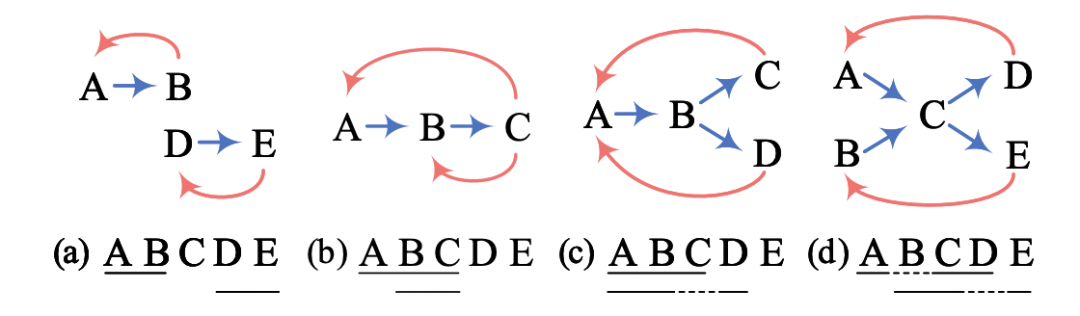
-
a): AB和CD代表两个扁平实体; -
b): 实体BC嵌套在实体ABC中; -
c): 实体ABC嵌套在非连续实体ABD; -
d): 两个非连续实体ACD和BCE;
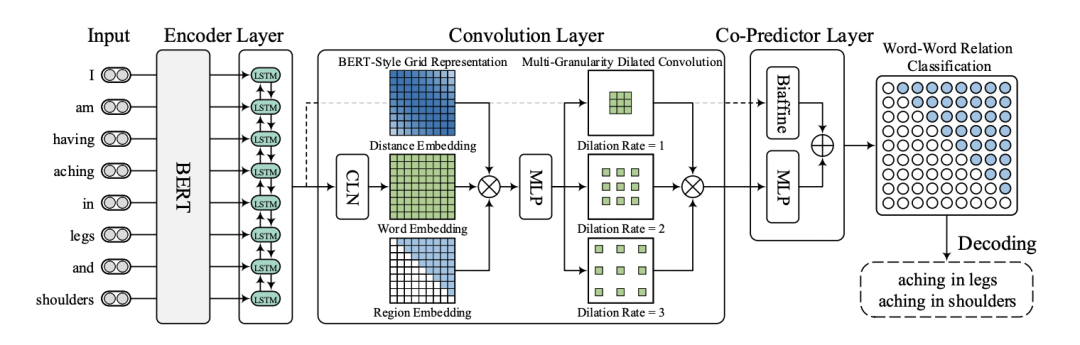
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢