
【论文标题】Pretrained transformer framework on pediatric claims data for population specific tasks
【作者团队】Xianlong Zeng, Simon L. Linwood & Chang Liu
【发表时间】2022/03/07
【机 构】俄亥俄大学、全国儿童医院
【论文链接】https://www.nature.com/articles/s41598-022-07545-1
【代码链接】https://github.com/drxzeng/Claim-PT
在过去的十年中,电子健康记录已经变得普遍,这为基于数据的深入研究提供了条件。通过从大量的医疗数据中学习,各种数据驱动的模型已经被建立起来,以预测不同医疗任务的未来事件,如自动诊断和心脏病预测。虽然EHR的数据很丰富,但满足特定人群学习任务的却很少,这使得训练对数据要求很高的深度学习模型具有挑战性。本研究提出了理赔预训练框架,这是一个通用的预训练模型,首先对整个儿科理赔数据集进行训练,然后对每个特定人群的任务进行辨别性微调。医疗事件的语义可以在预训练阶段被捕捉到,而有效的知识转移则通过任务感知的微调阶段完成。微调过程需要在不改变模型结构的情况下进行最小的参数修改,这就缓解了数据稀缺的问题,并有助于在小型患者群中充分训练深度学习模型。本文在一个拥有超过一百万条病人记录的真实世界儿科数据集上进行了实验。在两个下游任务上的实验结果证明了本文方法的有效性:本文的通用任务诊断预训练框架的表现优于定制的特定任务模型,与基线相比,模型性能提高了10%以上。此外,本文的框架显示了将学到的知识从一个机构转移到另一个机构的潜力,这可能为未来跨机构的医疗模型预训练铺平道路。
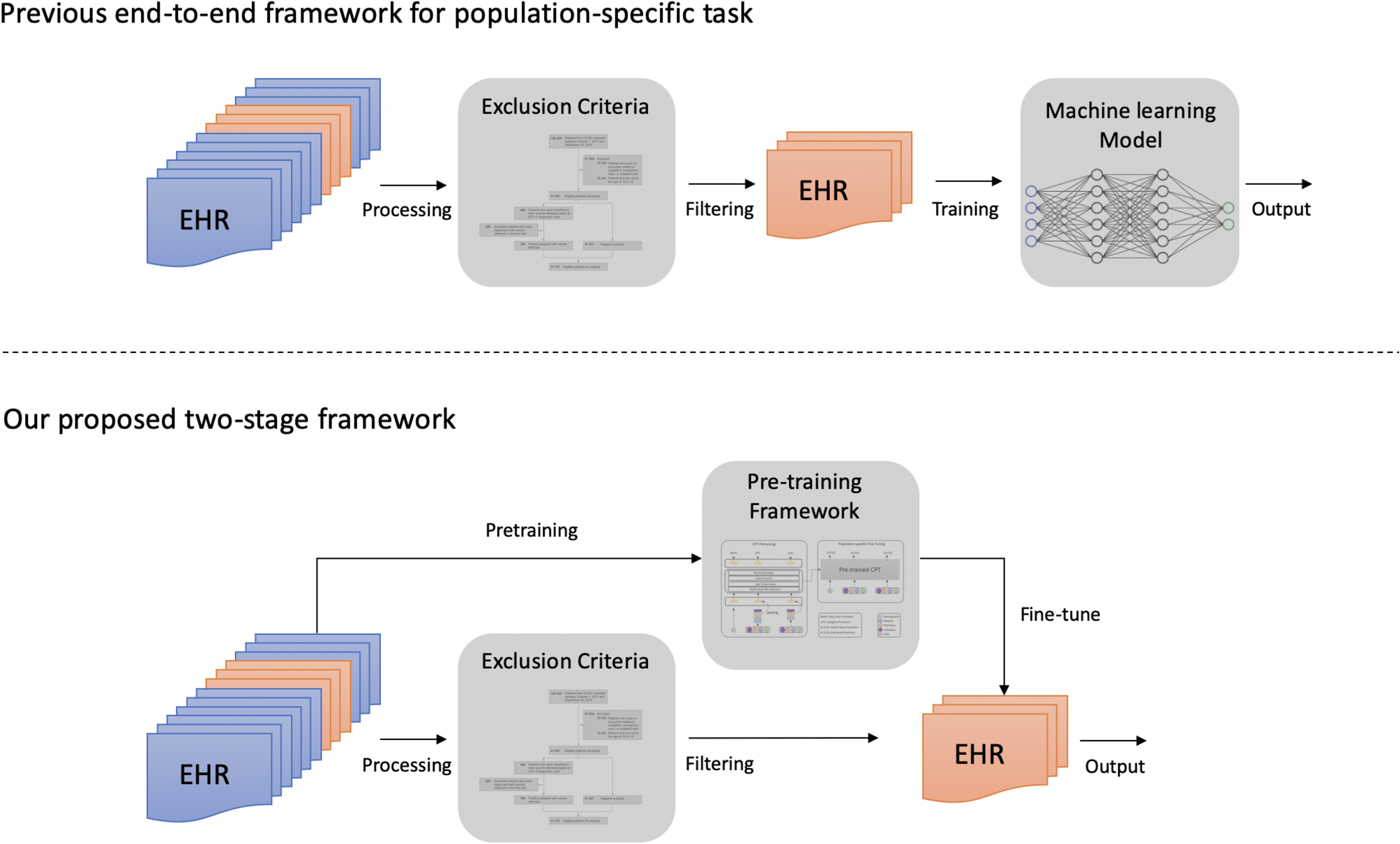
上图展示了传统思路和本文提出的预训练方法思路。大多数医疗预测任务的传统方法需要严格的标准来构建病例和对照病人队列,削弱了深度学习模型的预测能力,导致了次优的性能。我们提出的预训练和微调框架利用了被排除的病人记录,大大提升了模型的性能。
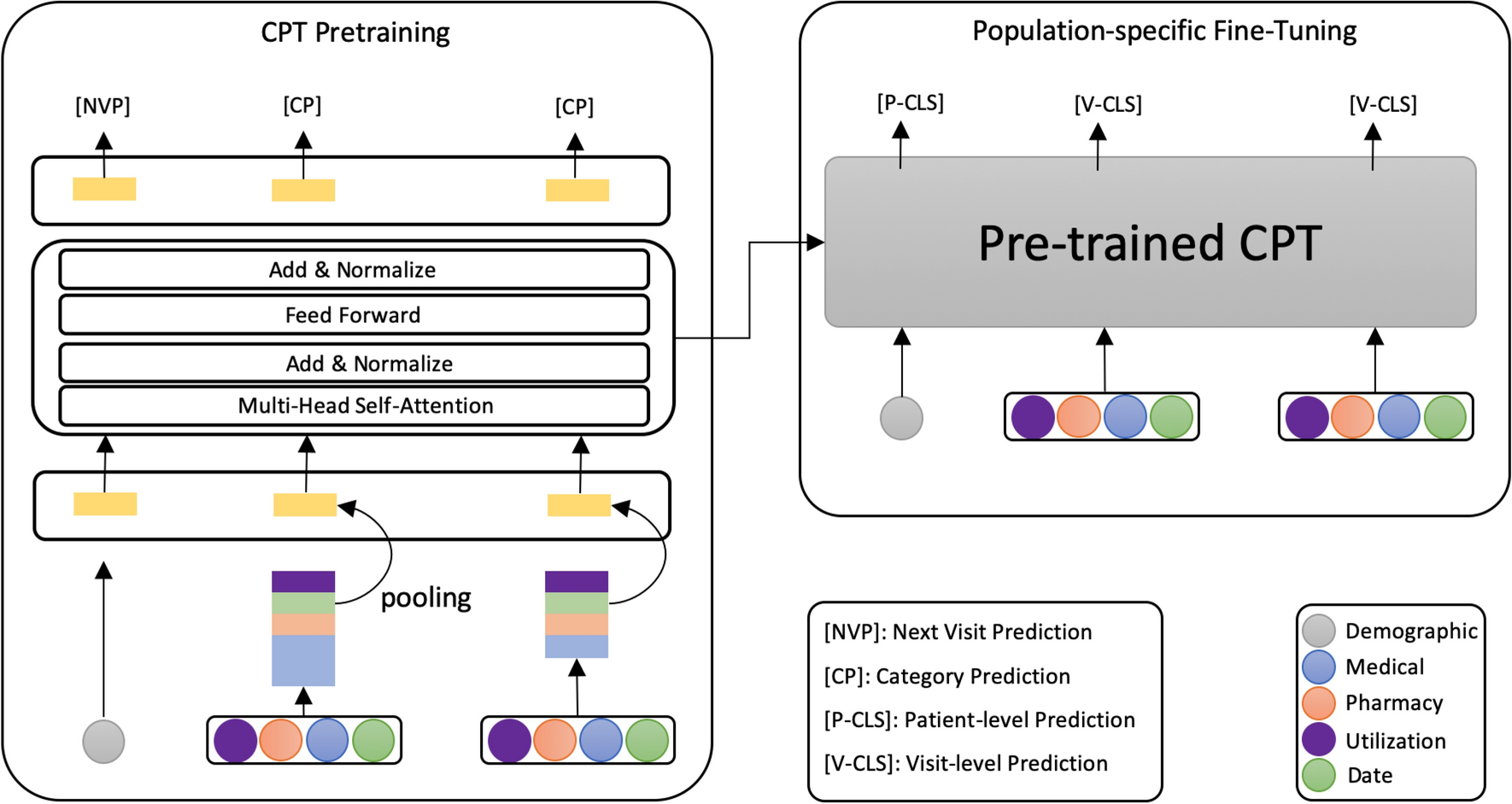
上图展示了预训练框架。几个任务分别为,
Next Visit Prediction (NVP):在下一次访问中最大限度地提高医疗代码的likelihood
Categorial Prediction (CP):旨在缓解罕见医疗编码的稀疏问题,引导模型学习能够代表相应代码类别的表征,将医疗代码的本体知识注入到嵌入过程中,迫使访问编码器提取有效信息,从而提高预训练模型的性能。
本文训练并公开发布了Claim-PT,这是一个基于Transformer的框架,在一个大型的真实世界的儿科理赔数据库中训练。据本文所知,Claim-PT是第一个在儿科理赔数据上进行预训练和微调的框架,它可以为特定人群的预测任务提供显著的性能提升。
本文证明,本文的框架可以利用一般的理赔记录来理解医疗知识。预训练的框架有助于改善下游特定人群的医疗预测任务,并优于定制的特定任务基线。此外,本文表明预训练的框架在跨机构的知识普及方面有很大的潜力,为未来医疗机构之间的护理协调和提供铺平了道路。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢