
【论文标题】Active label cleaning for improved dataset quality under resource constraints
【作者团队】Mélanie Bernhardt, Daniel C. Castro, Ryutaro Tanno, Anton Schwaighofer, Kerem C. Tezcan, Miguel Monteiro, Shruthi Bannur, Matthew P. Lungren, Aditya Nori, Ben Glocker, Javier Alvarez-Valle & Ozan Oktay
【发表时间】2022/03/04
【机 构】微软
【论文链接】https://www.nature.com/articles/s41467-022-28818-3
【代码链接】 https://github.com/microsoft/InnerEye-DeepLearning/tree/main/InnerEye-DataQuality
数据注释中的缺陷,即标签噪声,对机器学习模型的训练是有害的,并对模型性能的评估有干扰作用。然而,在资源受限的情况下,例如在医疗保健领域,雇用专家通过对大型数据集进行全面重新注释来消除标签噪声是不可行的。这项工作主张采用一种数据驱动的方法来确定重新标注样本的优先次序--作者称之为 "主动标签清理"。作者建议根据每个样本的估计标签正确性和标签难度对实例进行排序,并引入一个模拟框架来评估重新标注的效果。作者在自然图像和医学成像基准上的实验表明,清理噪声标签可以减轻它们对模型训练、评估和选择的负面影响。最重要的是,所提出的方法能够在现实条件下比典型的随机选择更有效地纠正标签,更好地利用专家的宝贵时间来提高数据集质量。
自监督预训练被证明是其中一种可靠的分类模型的替代方案,其性能优于从头开始训练的抗噪声模型,随着未标记数据集可用性的增加更加优秀。即使监督式的标签有噪声,获取新标签也可以通过回收数据样本来补充 NRL,并且还可以处理有偏差的标签。因此,主动标签清理和自监督可以结合起来,不仅可以获得更好的模型,还可以为下游应用程序提供干净的数据标签。
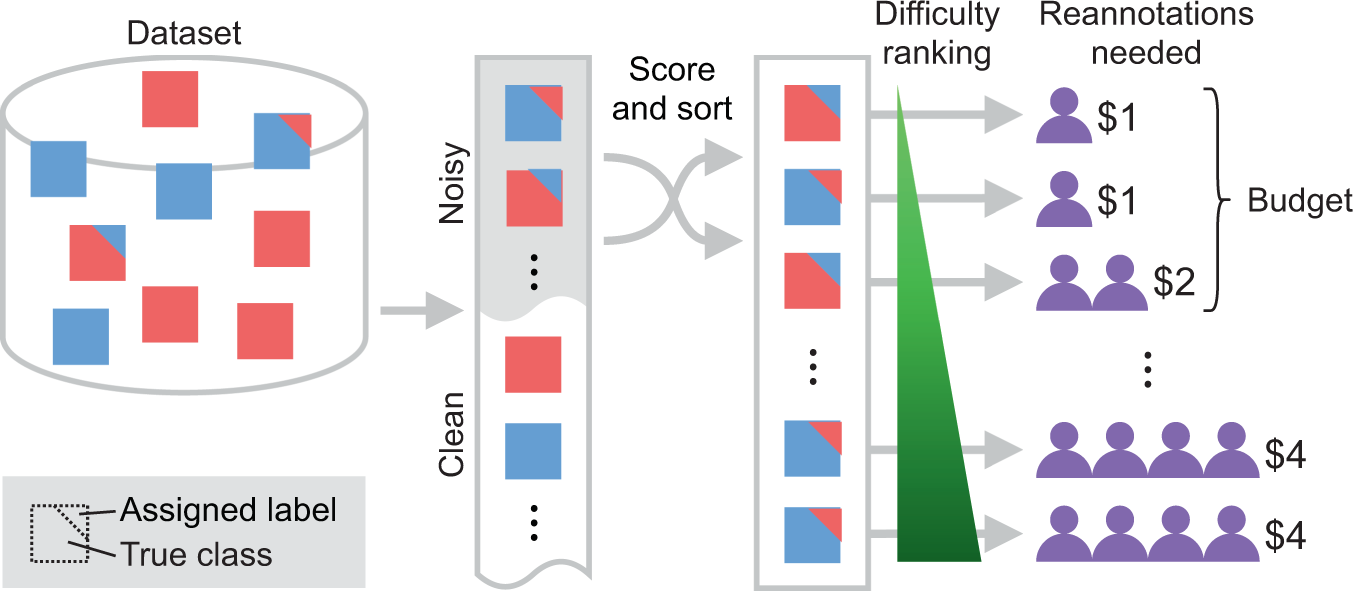
上图展示了对具有噪声标签的数据集进行排序,以优先处理明显的错误标签样本,在固定的重标预算下,最大限度地提高纠正样本的数量。

上图展示了主动标签清洗的算法流程。算法根据来自训练好的分类模型的预测后验,pθ(y^|x),用θ来参数化,来决定标签的优先级。标签清理在多个迭代中进行,在每个迭代中,单个或一批样本被重新标记。在一次迭代中,首先根据预测的标签正确性和模糊性(见评分函数Φ)对样本进行排名。然后,每个被优先考虑的样本由不同的注释者依次标注,直到在所有收集的标签中形成多数。在下一次迭代中,剩余的样本被重新优先处理,该过程重复进行,直到重新贴标预算用完。另外假设每个注释都有一个固定的成本,一个样本的注释越多,其重新标注的成本就越高。因此,为明显标记错误的样本需要更优先,而正确标记的样本应该有最低的重标记必要性。
本文建议通过评分函数Φ(噪音减去模糊度)对样本进行排序,
1.噪音定义为从归一化标签计数到预测后验的交叉熵。对应于给定标签的估计噪声(即负对数可能性)。交叉熵通常被用于NRL,通过对损失值进行排序来检测错误的样本。
2.模糊度使用获得多数标签投票需要对不同的图像进行不同数量的重新注释,这取决于其难度。这可以通过定义在后验上的熵项H(pθ)来量化。它对排名中的模棱两可的情况进行惩罚。在主动学习方法中,这个数量也被用作对不确定性(即数据模糊性)的估计,它对模糊的样本进行优先排序,以解决像注释预算约束。这个数量可以通过对θ的分布进行边际化来更好地估计。类似的目标也被用在半监督学习和熵正则化的背景下。
3.框架允许在清洗过程中定期更新模型;因此,选择器模型可以在任何时候使用迄今为止收集到的修正标签进行微调,这已被证明可以提高清洗性能。
本文创新点:
1.本文首先用精确的术语定义了主动标签清理设置,以及提议的重新标记优先级分数。
2.作者使用自然图像和胸部X光片的数据集,通过实验证明了标签噪声对训练和评估预测模型的负面影响,以及清洁噪声标签如何能减轻这些影响。
3.作者通过模拟表明,所提出的主动标签清理框架可以在资源有限的情况下有效地确定重新注释的样本的优先次序,比天真的随机选择节省大量资金。
4.作者分析了鲁棒学习和自监督技术如何能进一步提高标签清理的性能。
5.作者验证了作者对评分函数的选择,该函数考虑了样本的难度和噪声水平,与主动学习基线进行了比较。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢