

近年来, 计算机视觉领域涌现出一大批有效的自监督预训练模型,如 NPID、SimCLR、MoCo 等,它们能够从大规模数据集中通过自监督的方式学习潜在的图像语义表征,从而提升预训练模型在各项下游任务(如物体分类、目标检测、语义分割)的迁移性能。
这些自监督预训练框架通常基于对比学习实现. 对比学习通过定义正负样本对,并在表征空间中最大化正样本对之间的相似度而最小化负样本对之间的相似度, 从而达到「同类相吸、异类互斥」的目的。在不可获得分类标签的情况下,NPID、MoCo、SimCLR 通过实例判别 (Instance Discrimination) 任务,将同一图像经过不同随机数据增强后作为正样本对,而将不同图像作为负样本对,从而学习对数据增强具有不变性的图像表征。
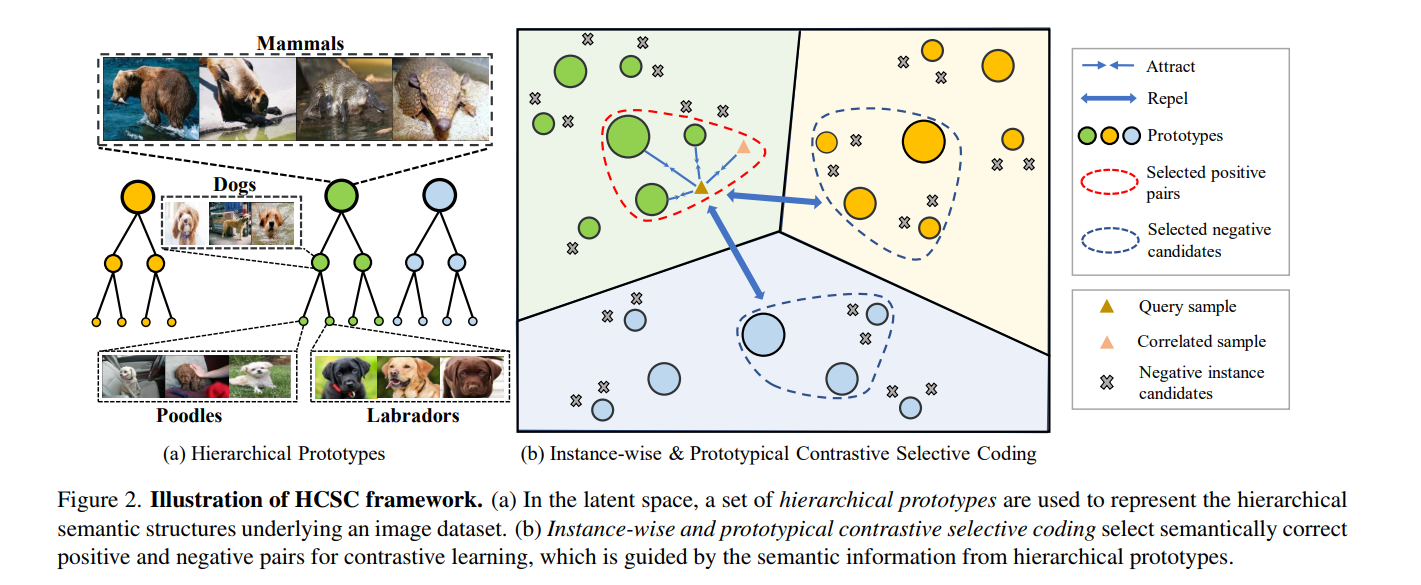
然而, 现有的自监督对比学习框架存在两个问题:
-
缺乏对上述层级语义结构的建模;
-
负样本对的定义可能存在噪声:随机选择的两张图像可能属于相同类别。
针对这两个问题,来自上海交通大学、Mila 魁北克人工智能研究所和字节跳动的研究者提出了一种基于层级语义结构的选择性对比学习框架(Hiearchical Contrastive Selective Coding,HCSC)。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢