
作者:Greg Yang , Edward J. Hu , Igor Babuschkin ,等
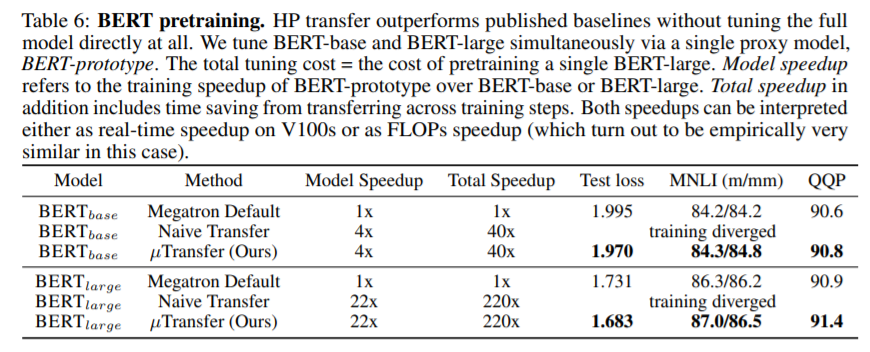
简介:本文研究大型预训练模型的超参数调整策略。深度学习中的超参数(HP)调整是一个昂贵的过程,对于具有数十亿参数的神经网络(NNs)来说也是如此。作者发现,在最近发现的最大更新参数化(muP)中,许多最优HPs即使在模型尺寸变化时也保持稳定。这就产生了一种新的HP调整模式,作者称之为muTransfer:在muP中对目标模型进行参数化,在较小的模型上间接调整HP,然后零样本将它们转移到全尺寸模型,即根本不直接调整后者。作者在Transformer和ResNet上验证相互传输,例如:1)通过将预训练HPs从一个包含13M个参数的模型中转移出来,作者的性能优于已公布的大量BERT large(350M个参数),总的调整成本相当于预训练BERT large一次;2) 通过从4000万个参数转换,作者的性能优于 GPT-3模型的公布数量:6.7B,调整成本仅占总预训练成本的7%。作者技术的Pytorch实现可以在文中的 URL上找到,并且可以通过“pip install mup”安装。
论文下载:https://arxiv.org/pdf/2203.03466.pdf
代码地址:https://github.com/microsoft/mup
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢