
作者:Shengnan An, Yifei Li, Zeqi Lin,等
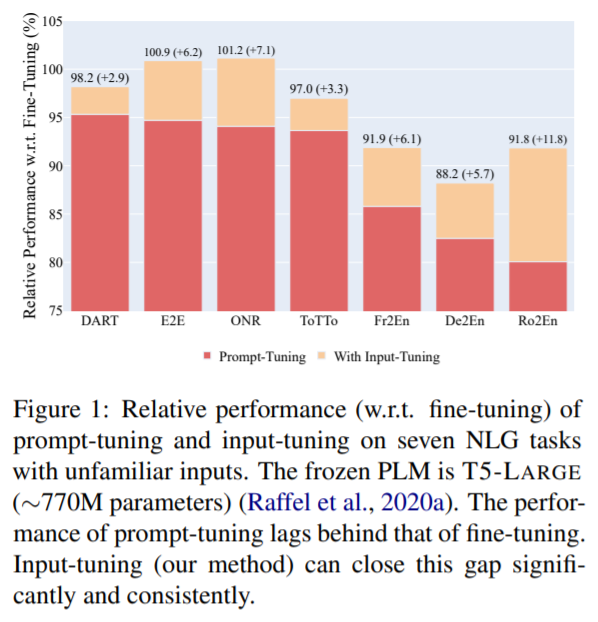
简介:本文研究自然语言生成领域中效果更优的Input-Tuning微调策略。最近,Prompt-Tuning范式引起了极大的关注。通过仅仅对冻结的预训练语言模型 (PLM) 持续地提示调优,在为服务众多下游任务而部署共享的冻结 PLM的方向上, Prompt-Tuning已迈出了前进的一步。尽管Prompt-Tuning在某些自然语言理解 (NLU) 任务上表现出良好的性能,但其在自然语言生成 (NLG) 任务上的有效性仍然有待探索。在本文中,作者认为阻碍 NLG 任务Prompt-Tuning发展的因素之一是不熟悉的输入(即输入在语言上与预训练语料库不同)。例如,作者的初步探索揭示了当 NLG 任务中频繁出现不熟悉的输入时,Prompt-Tuning和微调之间存在很大的性能差距。这促使作者提出Input-Tuning策略:对连续提示和输入表示进行微调,从而以更有效的方式将不熟悉的输入适应于冻结的 PLM。作者提出的Input-Tuning在概念上很简单,并且在经验上很强大。七个 NLG 任务的实验结果表明,Input-Tuning明显且始终优于Prompt-Tuning。此外,在其中三个任务上,Input-Tuning可以达到与微调相当甚至更好的效果。

论文下载:https://arxiv.org/pdf/2203.03131.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢