

代码:https://github.com/TuSimple/SST
论文:https://arxiv.org/pdf/2112.06375.pdf
摘要
在基于LiDAR的自动驾驶3D目标检测任务中,检测物体与场景大小的比例呈现出超过2D检测的现象。因此,许多3D检测器直接使用2D检测器的常规方法,即在量化点云之后对特征图进行下采样。本文作者重新思考了这种固定思路对3D点云目标检测的影响。实验结果表明,下采样方法不仅无法带来优势,还会不可避免地造成信息损失。为了解决这个问题,本文提出了一种Single-stride Sparse Transformer (SST)来保持网络特征的空间尺寸。利用Transformer模型,SST不仅解决了已有方法中感受野不足的问题,还能够配合点云的稀疏性以降低计算代价。SST在大规模的Waymo开放数据集上也取得了最先进的结果,且该方法对小物体(行人)检测具有单步幅(Single-stride)的特点,在验证集上可达到83.8 LEVEL_1AP。
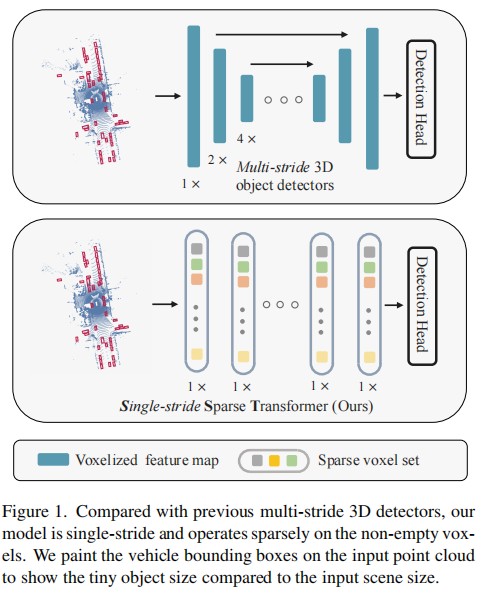
动机
二维图像检测的目标尺寸呈现长尾分布,且总体比例偏大,多尺度(Hierarchical)网络的结构非常适合。然而,如下图所示,3D点云目标检测的问题之一在于:目标尺寸占场景尺寸的比例非常非常小,且点云中物体尺寸都很小,由此,作者发问:点云目标检测中下采样的多尺度网络的作用是什么?
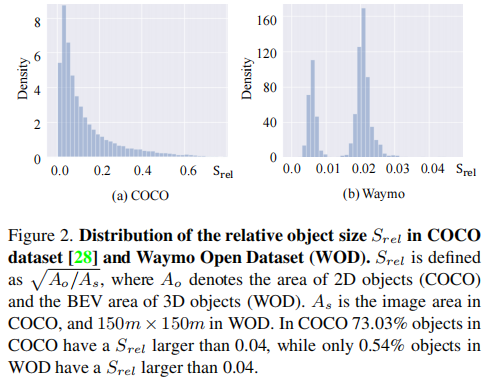
在已有研究中,特征下采样是一种常规的操作,不进行下采样会带来两个问题:计算消耗的增大和感受野的下降。针对这两个问题,作者实践了两种常规的方法:空洞卷积和大卷积核。
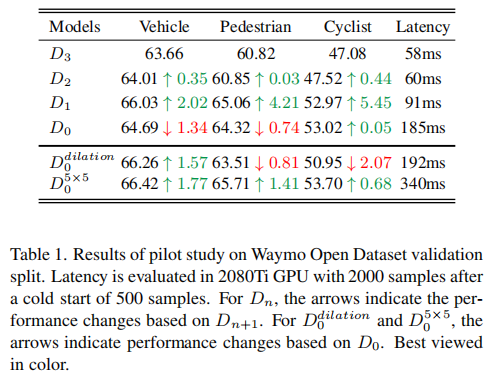
在表1中,D代表空洞卷积,D4至D0的步长配置为:{1; 2; 4; 8}, {1; 2; 4; 4}, {1; 2; 2; 2} 和 {1; 1; 1; 1},结果表明:
- 从D3—>D2—>D1,较小步长有利于点云三维目标检测;从D1—>D0,对于车辆的较大物体D0的步长的感受野不够,对于较小尺寸的行人和自行车足够;上述结果验证了感受野对点云三维目标检测结果影响的猜想。
- 空洞卷积增加了感受野,使得车辆检测性能得到了提升,但同时牺牲了检测的精细度,使得行人和自行车等小目标的性能下降了。
- 增大的卷积核确实有效果,在各个目标上都提升了性能,但是计算时间已经来到了一个非常大的数值。
因此,作者对点云目标检测模型提出了以下设计思路:单一尺度结构、充分的感受野,以及可接受的计算消耗。
方法
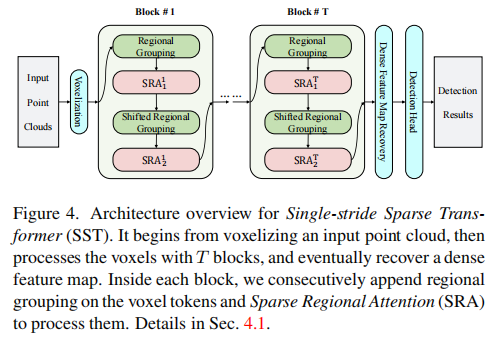
本文提出的SST结构如上图所示,给定输入点云数据,首先使用VoxelNet、ECOND、Pointpillars等特征编码网络得到特征F。接着将它们划分为不重合的区域(Regional Grouping),送入稀疏注意力模块(Sparse Regional Attention)。为了解决目标尺度不一的问题,进一步通过偏移窗口(shift window)进行目标区域的再次划分,并使用稀疏注意力模块进行处理。
区域划分
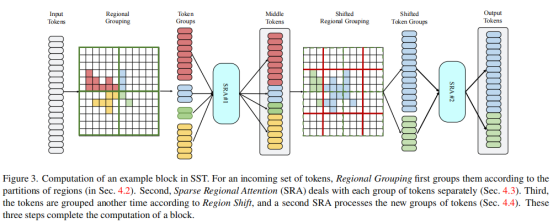
对于传入的特征F,本文将其视为不同的Token序列。首先根据他们的空间位置进行分组。接着,稀疏注意力模块分别处理不同区域的Token。然后,根据Region Shift将Token再次分组,使用另一个稀疏注意力模块处理新的Token组。
稀疏注意力模块
对于划分后的Token序列,稀疏注意力模块采用传统的Transformer操作进行计算:
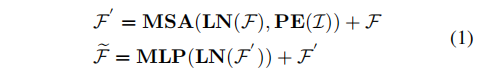
其中LN表示Layer Normalization,PE表示absolute positional encoding function,MSA是多头自注意力模块。作者进一步提出如下约束以利用点云的稀疏性:
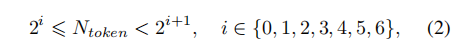
即要求Token序列中的点数处于一个合理的较小区间。
最后,作者考虑到单阶段(one-stage)检测器和双阶段(two-stage)检测器之间有相当大的性能差距,选择LiDAR-RCNN作为第二级探测器构成一个双阶段检测器。LiDAR-RCNN是一个轻量级的网络,由一个简单的PointNet组成,它被用于提取原始点云输入的特征。
实验
本文在Waymo开放数据集上进行了实验。该数据集共包含1150个序列(超过200K帧),其中798个序列作为训练集,202个序列用于验证集,150个序列构成测试集。
车辆检测结果
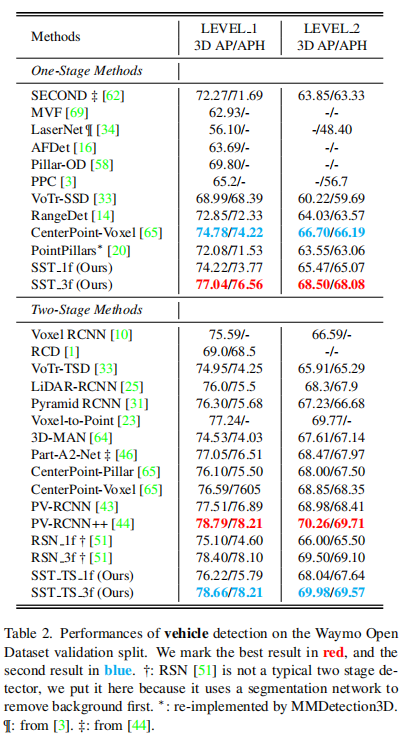
从下表可以看出,单阶段模型中,SST_1f的性能略低于CenterPoint,但SST_3f有大幅度的性能涨点;双阶段模型中,SST_TS_1f的表现一般,但SST_TS_3f较为显著地超越了大部分对比模型。
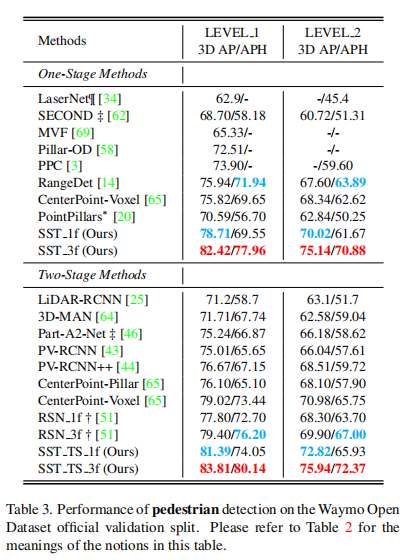
行人检测结果
从下表可以看出,SST_1f就可以达到SOTA的效果,且领先对比方法的性能较多,这说明SST固定步长结构的设计减少了信息损失,与周围远近的点都进行充分交互,使得其在小目标检测中表现非常突出。
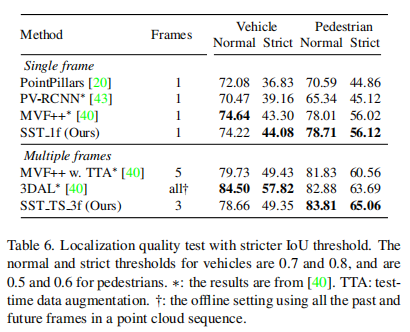
IoU阈值
进一步地,为了探究定位精度,将IoU阈值设置地更小使得检测结果更加严格。在单帧方法中,对比MVF++*,SST在正常IoU阈值下比不过,但是小阈值时可以超过该模型,说明SST在定位精度提升上有一定效果。值得一提的是,在多帧方法中,虽然SST在车辆检测上不如MVF和3DAL(CVPR2021 Qi在waymo提出的offboard检测方法),但是在行人检测上SST的检测结果比采用200帧的3DAL还有1个点的提升,说明了SST在小目标检测上的性能优势。
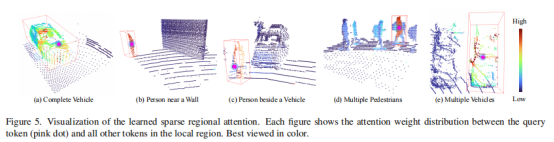
可视化分析
下图表示了点像素与周围像素的注意力权重分布,可以看到:与不相关点的权重较大,说明了本文稀疏注意力模块的有效性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢