
论文标题: CP-ViT: Cascade Vision Transformer Pruning via Progressive Sparsity Prediction
论文链接:https://arxiv.org/abs/2203.04570
作者单位:上海交通大学
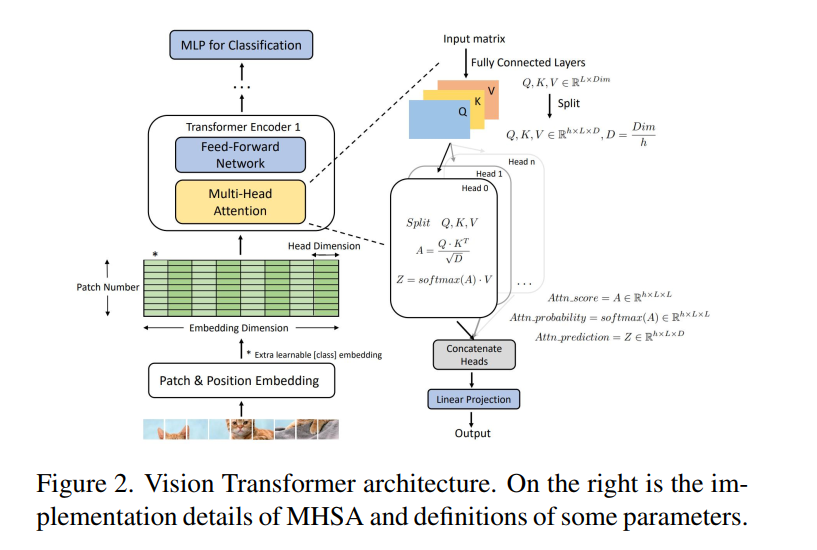
视觉Transformer (ViT) 在各种计算机视觉应用中实现了具有竞争力的精度,但其计算成本阻碍了在资源有限的移动设备上的部署。我们探索了 ViT 中的稀疏性,并观察到信息丰富的补丁和头部足以进行准确的图像识别。在本文中,我们提出了一个名为 CP-ViT 的级联修剪框架,通过逐步动态地预测 ViT 模型中的稀疏性来减少计算冗余,同时最大限度地减少精度损失。具体来说,我们定义累积分数以保留 ViT 模型中的信息补丁和头部,以获得更好的准确性。我们还提出了基于层感知注意力范围的动态修剪比率调整技术。 CP-ViT 对实际部署具有很强的通用性,可应用于范围广泛的 ViT 模型,无论是否进行微调都可以实现卓越的精度。使用各种预训练模型在 ImageNet、CIFAR-10 和 CIFAR-100 上进行的大量实验证明了 CP-ViT 的有效性和效率。通过逐步修剪 50% 的补丁,我们的 CP-ViT 方法减少了 40% 以上的 FLOP,同时将精度损失保持在 1% 以内。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢