

论文链接:https://arxiv.org/pdf/2203.03605v1.pdf
代码链接:https://github.com/IDEACVR/DINO
摘要
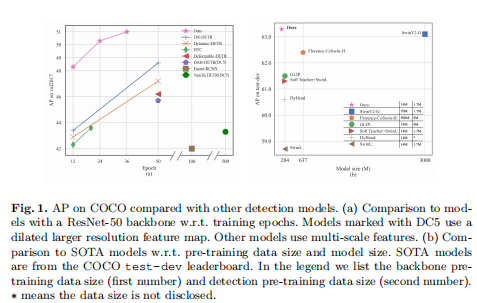
本文介绍了目前最有效的端到端对象检测器——DINO (DETR with Improved deNoising anchOr boxes)。DINO采用对比学习方法进行去噪训练,采用混合查询方法进行锚点初始化,采用重复推理机制进行目标框生成,在性能和效率上均超越了现有的DETR模型。通过将ResNet-50作为主干网络并设置多尺度特征,DINO仅训练12个epoch便可以得到51.0AP的检测精度,较之已有方法分别获得了+4.9AP和+2.4AP的显著提高。
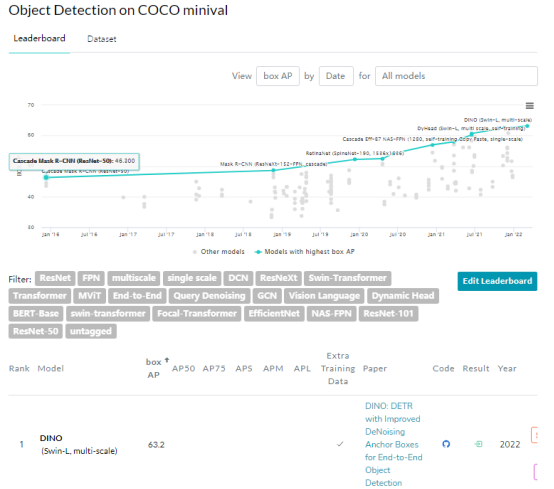
在使用用SwinL作为主干网络,并在Objects365数据集上进行预训练后,DINO在COCO val2017 (63.2AP)和COCO val2017(63.3AP)上都获得了最好的结果与排行榜上的其他模型相比,DINO显著降低了模型大小和训练前数据大小,同时取得更好的结果。
动机
DETR是2020年由Facebook AI提出并将Transformer引入Detection领域的开创性工作。DETR将目标检测看作一种集合预测(set prediction)问题,并提出了一个十分简洁的目标检测pipeline:主干 CNN提特征,送入Transformer通过attention机制做关联建模,得到的输出通过二分图匹配算法与图片上的ground truth计算损失函数。尽管DETR系列模型取得了较大的性能提升,但仍存在本文总结出的两个缺陷:
- 已有DERT系列模型在性能上仍逊于传统检测模型。
- 已有DERT系列模型的可扩展性(scalability)仍未充分探索。
为解决上述问题,本文分别提出了三个技术创新:
- Contrastive DeNoising Training。为了改善one-to-one匹配问题,训练的时候正样本和负样本同时加了噪声。添加smaller noise的作为正样本,其他作为负样本,主要目的是去重box。
- Mixed Query Selection。提升查询向量的初始化效果。
- Look Forward Twice。利用来自深层的精细目标框信息帮助优化模型的浅层参数。
方法
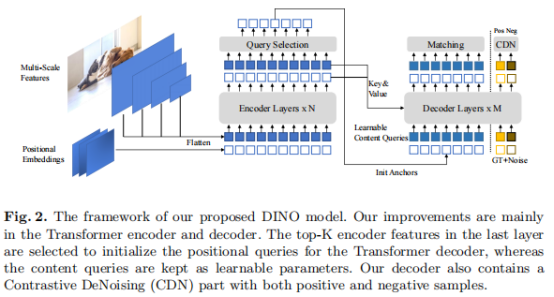
如上图所示,DINO是一个端到端模型,它包含一个主干网络、一个多层Transformer编码器、一个多层Transformer 编码器和多个预测头。给定一幅图像,DINO用ResNet或Swin Transformer等主干网络提取多尺度特征,然后将它们与相应的位置嵌入一起输入Transformer编码器。在对编码器进行特征增强后,DINO利用一种新的混合查询选择策略,将锚初始化为解码器的位置查询。
Contrastive DeNoising Training——对比去噪训练

不同于DN-DETR,DINO使用两个超参数λ1、λ2控制噪声尺度,λ1小于λ2。在生成4个维度的深度特征之后,DINO将它们视为同质空间中的2D特征点,假设一个图像有n个目标,则可以通过DN-DETR的方式将这些特征点形成n个簇,并通过超参数选择出positive、negative特征点计算重构误差。
Mixed Query Selection——混合查询选择
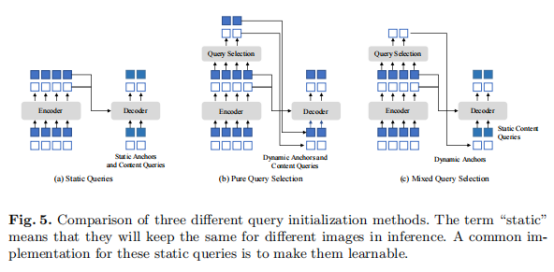
如上图中的子图(a)所示,DETR、DN-DETR中解码器的查询向量是静态的。通过学习一个动态选择变量,Deformable DETR能够利用图像中目标的位置和内容信息得到更好的效果。本文提出Mixed query selection进一步提升解码器查询向量的性能。在对比去噪训练中,特征被视为4D空间中的二维特征点,且超参数λ1、λ2能够使得部分特征倾向于目标的位置信息,部分特征倾向于其内容信息。因此,本文提出使用top-K特征增强位置信息的查询,并保持内容信息的查询向量可学习,这一思路可以帮助解码器使用更好的位置信息来学习目标的内容表观。
Look Forward Twice——重复推理机制
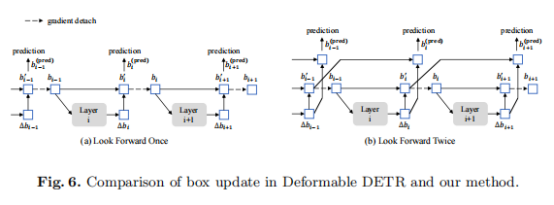
在Deformable DETR中,梯度信息被用于精炼训练过程中的目标框生成,这一思路已经证实能够较好地提升检测结果。因此,本文提出一种新的思路。如(b)图所示,模型中第i层的参数分别通过对比去噪训练中的不同特征点计算损失,并通过两次损失梯度进行更新。这使得模型会产生两次检测框b,因此,作者提出如下思路得到最终检测结果:
实验
本文在COCO 2017目标检测数据集进行评估,并使用了两个不同的主干网络:通过ImageNet-1k预训练的ResNet-50、在ImageNet-22k预训练的SwinL。使用ResNet-50的DINO直接在COCO 2017的训练集上进行训练,而使用SwinL的DINO首先在Object365[33]上进行预训练,然后在COCO 2017的训练集上进行微调。
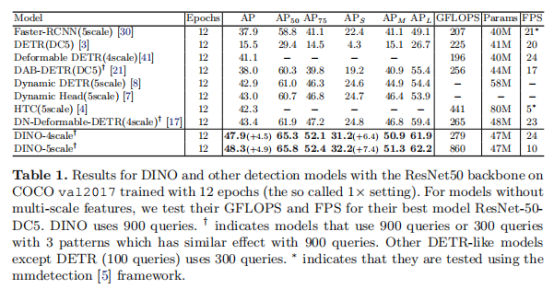
如表1所示,使用ResNet-50作为主干网络的DINO在相同的设置下得到了4.5 AP的改进。此外,DINO对小目标检测表现得特别好,在多个检测精度下获得6.4 AP和7.4 AP的性能提升。
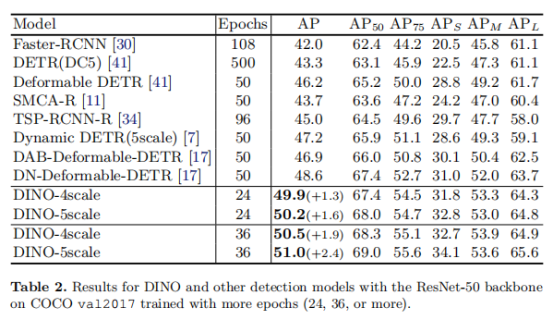
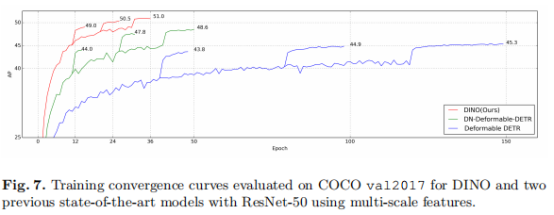
从表2可以看出,在仅使用24个epoch的情况下,DINO分别提高了+1.3 AP和+1.6 AP。此外,当训练36个epoch时,DINO-4scale、DINO-5scale分别增加了+1.9和+2.4 AP。具体收敛曲线对比如图7所示。
如表3所示,DINO在COCO val2017和test-dev子集上获得了63.2AP和63.3AP的最佳结果,这说明它对模型参数和数据规模具有很强的可扩展性。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢