
传统的帧插值通常都是在两张极其相似之间生成图像。最近Google提出的FLIM模型能够对动作变化幅度较大的两张照片进行帧插值来生成视频:首次引入Gram损失,不仅锐度提升,细节也拉满!
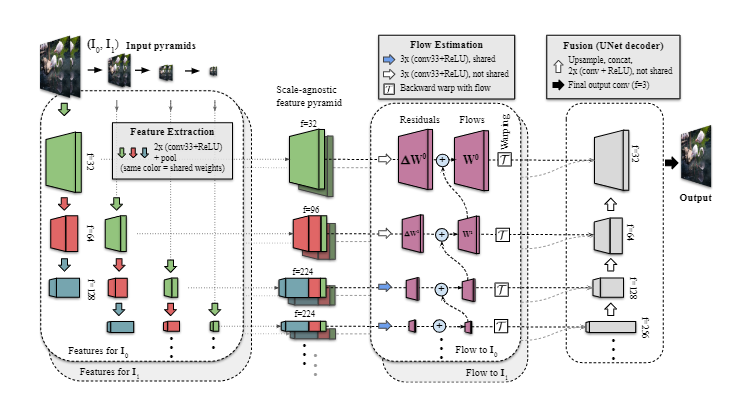
之前的帧插值模型往往很复杂,需要多个网络来估计光流(optical flow)或者深度,还需要一个单独的网络专门用于帧合成。而FLIM只需要一个统一网络,使用多尺度的特征提取器,在所有尺度上共享可训练的权重,并且可以只需要帧就可以训练,不需要光流或者深度数据。
FLIM的实验结果也证明了其优于之前的研究成果,能够合成高质量的图像,并且生成的视频也更连贯。代码和预训练模型都已开源。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢