
本文介绍我们在CVPR 2022关于基于文本和参考图像完成头发编辑的工作。该工作将文本和参考图像条件统一在了一个框架内,在单个模型内支持广泛的图像和文本作为输入条件从而完成相应的头发编辑任务。

论文标题: HairCLIP: Design Your Hair by Text and Reference Image
作者单位: 中国科学技术大学,微软云AI,香港城市大学
录用信息: CVPR 2022
代码:
https://github.com/wty-ustc/HairCLIP
论文:
https://arxiv.org/abs/2112.05142
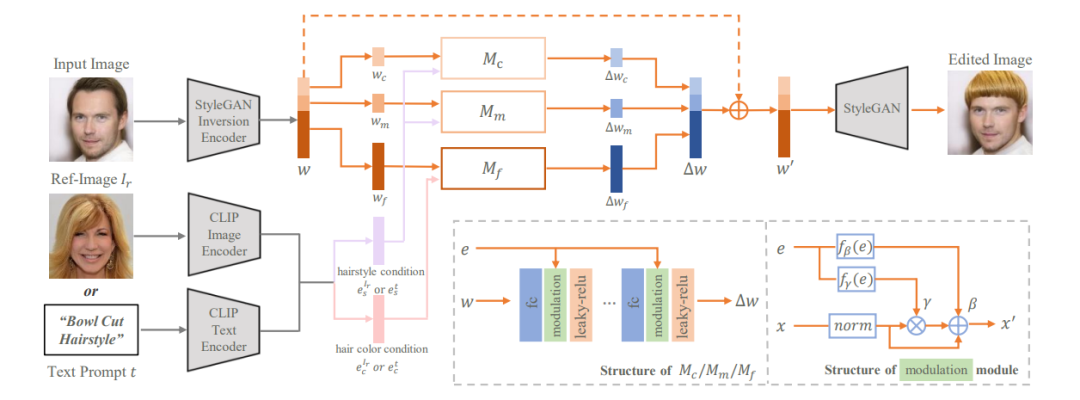
本文利用在大规模人脸数据集上预训练的StyleGAN作为我们的生成器,整个头发编辑框架如下图所示。给定待编辑的真实图像,我们首先使用StyleGAN inversion方法得到其隐编码,然后我们的头发映射器根据隐编码和条件输入(发型条件、发色条件)预测隐编码相应的变化,最后修改后的隐编码将被送入StyleGAN产生对应的头发编辑后的图像。因此,最核心的问题就是学习一个映射器网络来将输入的条件解耦地映射到隐编码的相应变化。我们从网络结构、损失函数两个方面来解决这个问题。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢