
作者:Canwen Xu, Daya Guo, Nan Duan,等
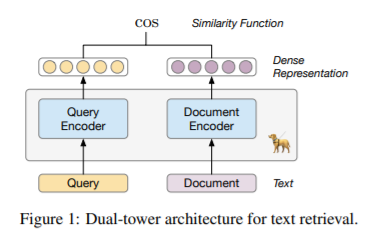
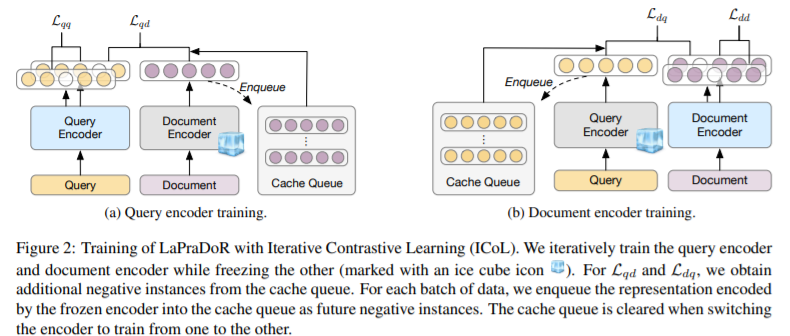
简介:本文研究基于预训练文本检索的无监督检索器。在本文中,作者提出了 LaPraDoR,这是一种预训练的双塔密集检索器,不需要任何监督数据进行训练。具体来说,作者首先提出了迭代对比学习 (ICoL),它使用缓存机制迭代地训练查询和文档编码器。ICoL 不仅扩大了负面实例的数量,而且还将缓存示例的表示保持在相同的隐藏空间中。然后,作者提出了词汇增强密集检索(LEDR)作为一种简单而有效的方法来通过词汇匹配来增强密集检索。作者在最近提出的 BEIR 基准上评估 LaPraDoR,包括 9 个零样本文本检索任务的 18 个数据集。实验结果表明,与监督密集检索模型相比,LaPraDoR 实现了最先进的性能,进一步的分析揭示了作者培训策略和目标的有效性。与重新排序相比,作者的词典增强方法可以在几毫秒内运行(快 22.5 倍),同时实现卓越的性能。
论文下载:https://arxiv.org/pdf/2203.06169
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢