
【标题】Lazy-MDPs: Towards Interpretable Reinforcement Learning by Learning When to Act
【作者团队】Alexis Jacq, Johan Ferret, Olivier Pietquin, Matthieu Geist
【发表日期】2022.3.16
【论文链接】https://arxiv.org/pdf/2203.08542.pdf
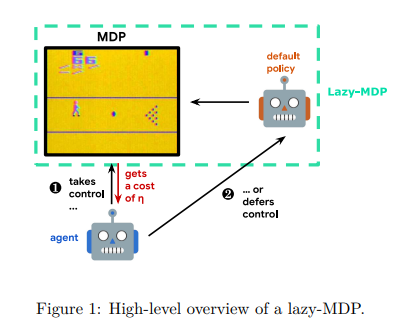
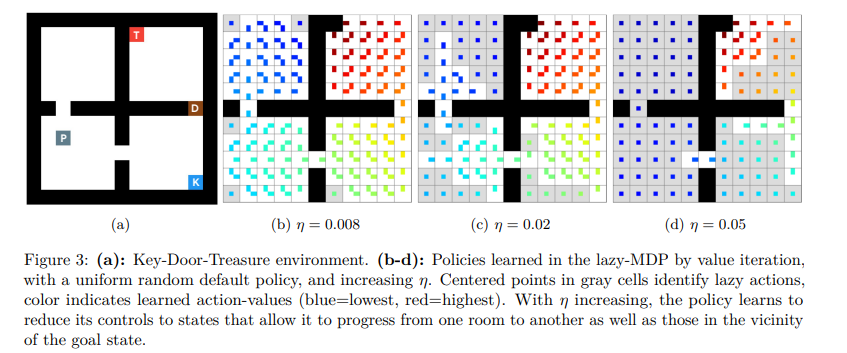
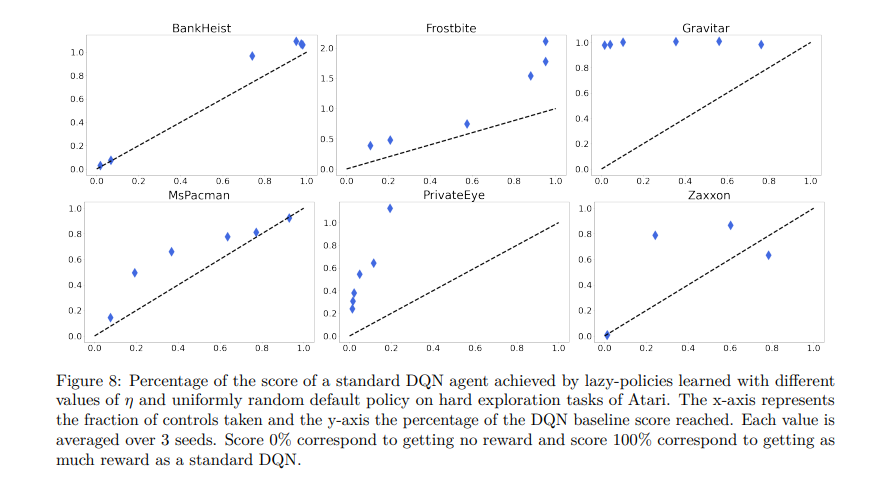
【推荐理由】传统上,强化学习(RL)旨在决定如何对人工智能体进行优化。本文认为,决定何时采取行动同样重要。为了增强具有这种能力的RL代理,本文提出增强标准马尔可夫决策过程,并提供一种新的行动模式:懒惰,这将决策推迟到默认策略。此外,该惩罚非懒惰行为,以鼓励最小的努力,并让代理只关注关键决策。将由此产生的形式主义命名为懒惰的MDP。其表达了价值函数和表征最优解。根据经验证明,在惰性MDP中学习的策略通常具有某种形式的可解释性:通过构造,其展示了智能体控制默认策略的状态。这些状态和相应的操作解释了默认策略和新的懒惰策略之间的性能差异。以次优策略作为默认策略(预训练或随机),在Atari游戏中,智能体能够获得竞争性性能,同时只在有限的状态子集中进行控制。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢