
本文为对话推荐系统设计了一种新的基于对比学习的粗粒度到细粒度的预训练方法。通过利用由粗到细的预训练策略,可以有效地融合多类型数据表示,从而进一步增强对话上下文的表示,最终提高CRS的性能。

论文链接:https://arxiv.org/abs/2201.02732
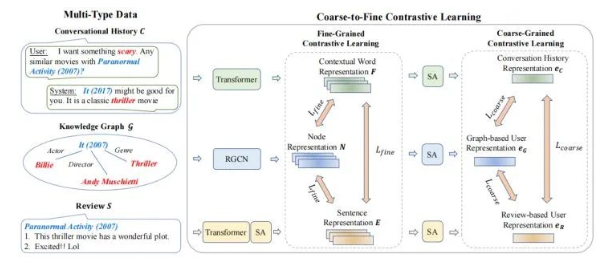
我们首先对不同类型的上下文数据进行编码。然后为了有效地利用多类型的数据,我们提出了一种由粗粒度到细粒度的对比学习框架,以改进 CRS 的数据语义融合。我们首先从不同的数据信号中提取和表示多粒度语义单元,然后以由粗粒度到细粒度的方式对齐关联的多类型语义单元。为了实现这个框架,我们设计了粗粒度和细粒度的预训练,前者侧重于更一般的、粗粒度的语义融合,后者侧重于更具体的、细粒度的语义融合。这种方法可以扩展到合并更多种类的外部数据。基于学习到的表示,我们构建了推荐模块和对话模块以完成各自任务。我们的模型图如下所示。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢