
作者:Le Hou, Richard Yuanzhe Pang, Tianyi Zhou,等
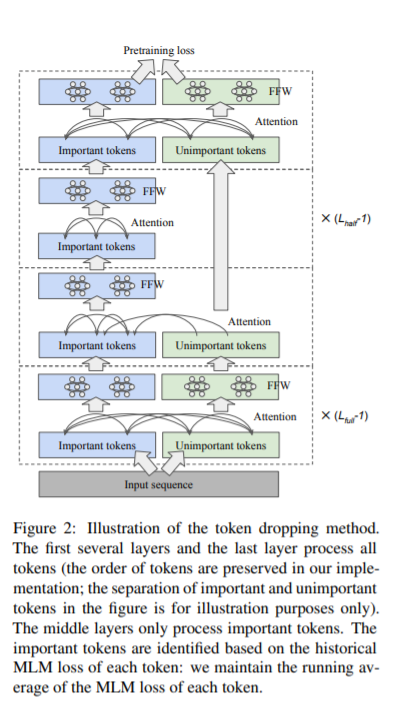
简介:本文研究“丢弃不重要的令牌”以降低Bert预训练成本。基于transformer的模型通常为给定序列中的每个令牌分配相同的计算量。作者开发了一种简单但有效的“令牌丢弃”方法来加速transformer模型(如BERT)的预训练,而不会降低其在下游任务中的性能。简言之,作者从模型的中间层开始丢弃不重要的令牌,使模型关注重要的令牌;丢弃的令牌稍后会被模型的最后一层拾取,这样模型仍然会生成完整的序列。作者利用已经内置的遮罩语言建模(MLM)损失来识别不重要的令牌,几乎没有计算开销。在作者的实验中,这种简单的方法将BERT的预训练成本降低了25%,同时在标准下游任务上实现了类似的整体微调性能。
论文下载:https://arxiv.org/pdf/2203.13240
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢