
论文标题:Beyond Fixation: Dynamic Window Visual Transformer
论文链接:https://arxiv.org/abs/2203.12856
代码链接:https://github.com/pzhren/DW-ViT
作者单位:西北大学 & 悉尼科技大学 & 中山大学
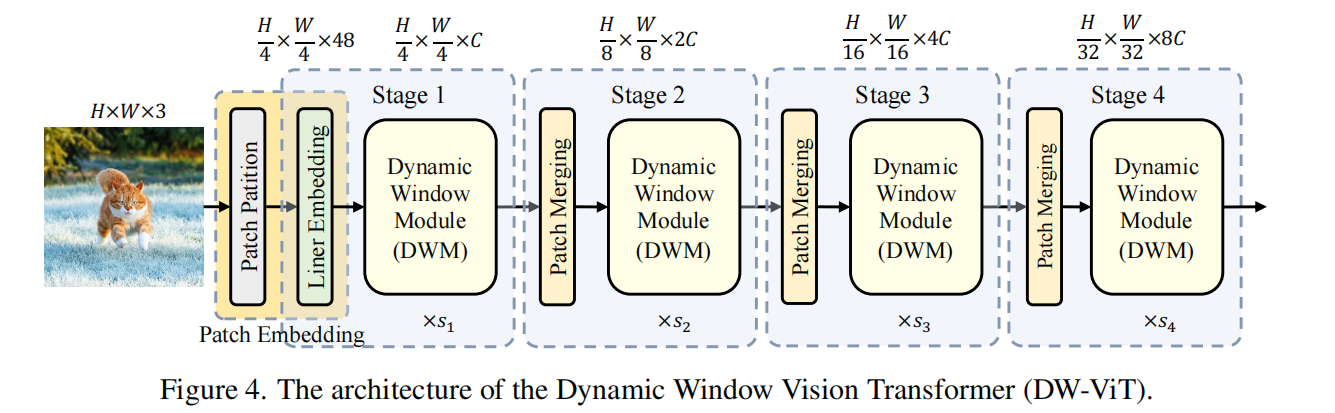
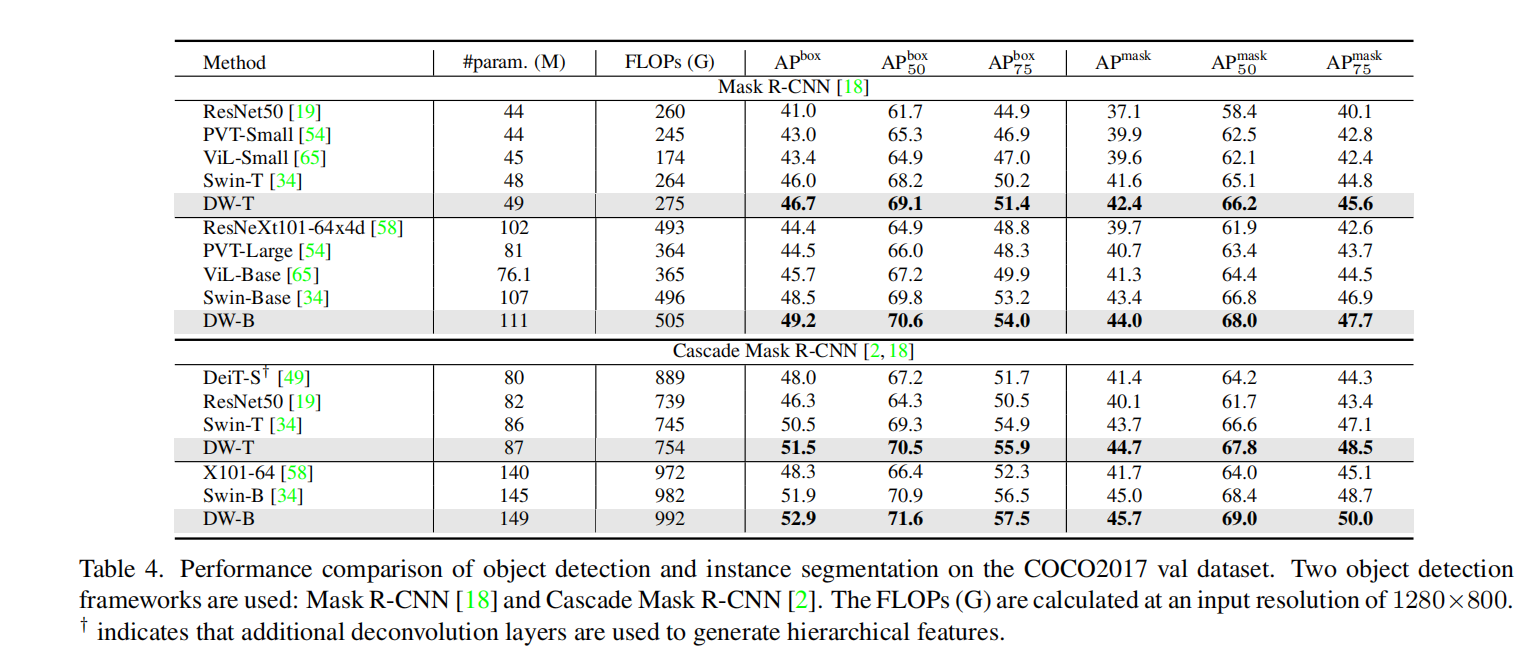
最近,对视觉Transformer的兴趣激增是通过将自注意力的计算限制在局部窗口来降低计算成本。目前大多数工作默认使用固定的单尺度窗口进行建模,忽略了窗口大小对模型性能的影响。然而,这可能会限制这些基于窗口的模型对多尺度信息的建模潜力。在本文中,我们提出了一种新方法,称为动态窗口视觉Transformer(DW-ViT)。 DW-ViT 提出的动态窗口策略超越了采用固定单窗口设置的模型。据我们所知,我们是第一个使用动态多尺度窗口来探索窗口设置对模型性能影响的上限的。在 DW-ViT 中,通过将不同大小的窗口分配给窗口多头自注意力的不同头组来获得多尺度信息。然后,通过为多尺度窗口分支分配不同的权重来动态融合信息。我们对三个数据集 ImageNet-1K、ADE20K 和 COCO 进行了详细的性能评估。与相关的最先进(SoTA)方法相比,DW-ViT 获得了最佳性能。具体来说,与当前的 SOTA Swin Transformers [34] 相比,DW-ViT 在具有相似参数和计算成本的所有三个数据集上实现了一致且显着的改进。此外,DW-ViT 表现出良好的可扩展性,可以轻松插入任何基于窗口的视觉转换器。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢