

论文链接:https://arxiv.org/abs/2203.12868
代码链接:https://github.com/hunto/DyRep
摘要
结构重参数机制(Structural re-parameterization)在VGG类型的模型上取得了优越的性能,其性能提升优势也在多个领域上得到了证实。然而,已有研究大多对所有操作通过重参数机制进行结构增广,甚至包括一些对模型性能作用较小的操作也进行处理,这种机制必然导致了昂贵的计算代价。为解决该问题,本文设计了一种DyRep(Dynamic Re-parameterization)方案以最小代价引导训练,将重参数技术编码到训练过程中对网络结构进行动态进化。最小代价通过对模型损失最为关键的操作,并使用去参数化机制进行操作的紧凑表示。实验结果表明,DyRep可以提升ResNet18的性能达2.04%,同时训练耗时降低22%。
贡献
在深度学习的早期研究中,为了追求参数和结构对性能的提升效果,VGG、ResNet等模型具有了大量的模型参数和复杂的模型结构,但同时也造成了极大的计算负担。从这个角度来看,本文研究了一种关键的问题:如何增强神经网络工作的能力而不招致昂贵的计算开销和高推理复杂度?
结构重参数机制及其变体是解决上述问题的一种热门机制,该机制在训练中构造增广模型,并在推理过程中将其转换回原始模型。具体来说,这些方法通过在训练中将原始的卷积运算扩展为多个分支,然后将它们融合为一个卷积,从而在不降低精度的情况下提高模型的表示能力。然而,在扩展过程中,所有参数都进行了重构,这必然会将冗余的参数引入到后续的聚合过程中,进而导致次优的结构和昂贵的计算代价。
为了解决这一问题,本文作者提出了一种新的重参数化方法,称为DyRep,在训练过程中对进行动态演化网络结构,在推理过程中对原模型进行重新推导。其关键动机可以总结为:在训练过程中自适应地寻找对性能(或损失)贡献最大的操作,而不是对所有操作进行普遍的重新参数化,从而保证了重构网络的有效性和准确性。本文贡献可以总结如下:
- 提出了一种应用于训练的动态重参数化方法DyRep,旨在以最小的开销提高结构重参数机制的性能。
- DyRep可以直接适应下游任务中的结构图,这个特性极大地降低了计算成本。
- 关于图像分类及其下游任务的大量实验表明,DyRep方法在准确性和运行成本方面都优于已有方法。
方法
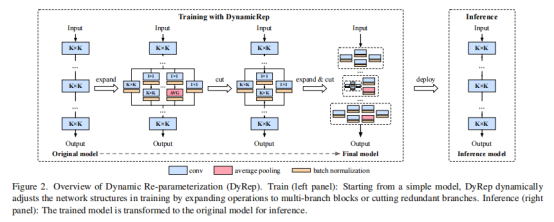
上图给出了本文所提DyRep方案的流程示意图,DyRep在训练阶段对网络贡献最大的分支进行自适应增广,而非常规的训练前“静态”增广方式。
通过动态结构减小损失(Minimizing Loss with Dynamic Structures)
在培训过程中,DyRep将重点放在增强网络中那些对减少损失贡献更大的操作上。因此,与DBB中将所有操作进行多分支的重构和复原,DyRep只重新参数化了造成最大损失的操作。在DyRep中,不同分支的贡献通过其梯度信息评估,也就是说:小梯度代表低贡献度,进而代表分支冗余。

基于已有研究synflow,参数的贡献度可以在损失L梯度的基础上通过下式计算得出:
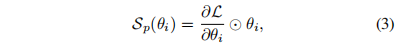
作者进一步将上式扩展到所有参数上,逐渐对贡献最大的分支进行重参数扩展:
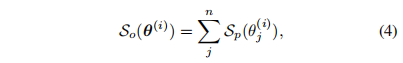
上式表明该方案可以进行递归重参数化以得到更丰富的表示形式。
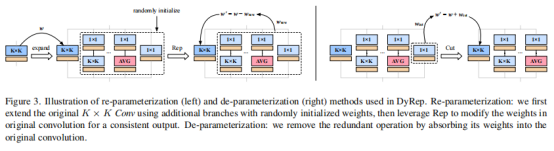
上图进一步给出了重参数流程:定位到重要的分支操作后,采用重参数技术将其从单一卷积扩展为DyRep模块,扩展分支的参数F随机初始化。为确保扩展前后的等价性,对其参数进行如下处理:
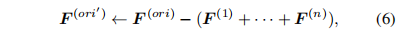
此外,为稳定训练,DyRep对所添加的BN层参数进行如下设置: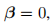
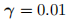 。对于均值与标准差进行20个batch的统计校正。
。对于均值与标准差进行20个batch的统计校正。
提升效率的去参数化(De-parameterizing for Better Efficiency)
除了对重要的模型分支进行重参数扩展外,DyRep还需要不重要的分支进行去冗余,称之为de-parameterization(Dep),其操作可以总结为下式:
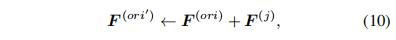
即要移除的分支参数折叠到重要的模型分支中。
去参数化和重参数化的迭代训练(Progressive Training with Rep and Dep)
通过提出的重参数化和去参数化技术,DyRep可以动态地丰富重要的模型操作,同时丢弃一些冗余的分支。

上图给出了DyRep训练流程说明,通过组合Rep与Dep,网络结构可以进行更高效的增广。具体来说,DyRep每t个epoch重复一次Rep与Dep操作:
- Rep:它包含最重要分支的选择、扩展以及参数修正;
- Dep:它包含冗余分支定位、移除以及参数修正。
实验
本文使用DBB中的实验设置,通过VGG-16、ResNet-18、ResNet-50在ImageNet数据集上进行性能比较。
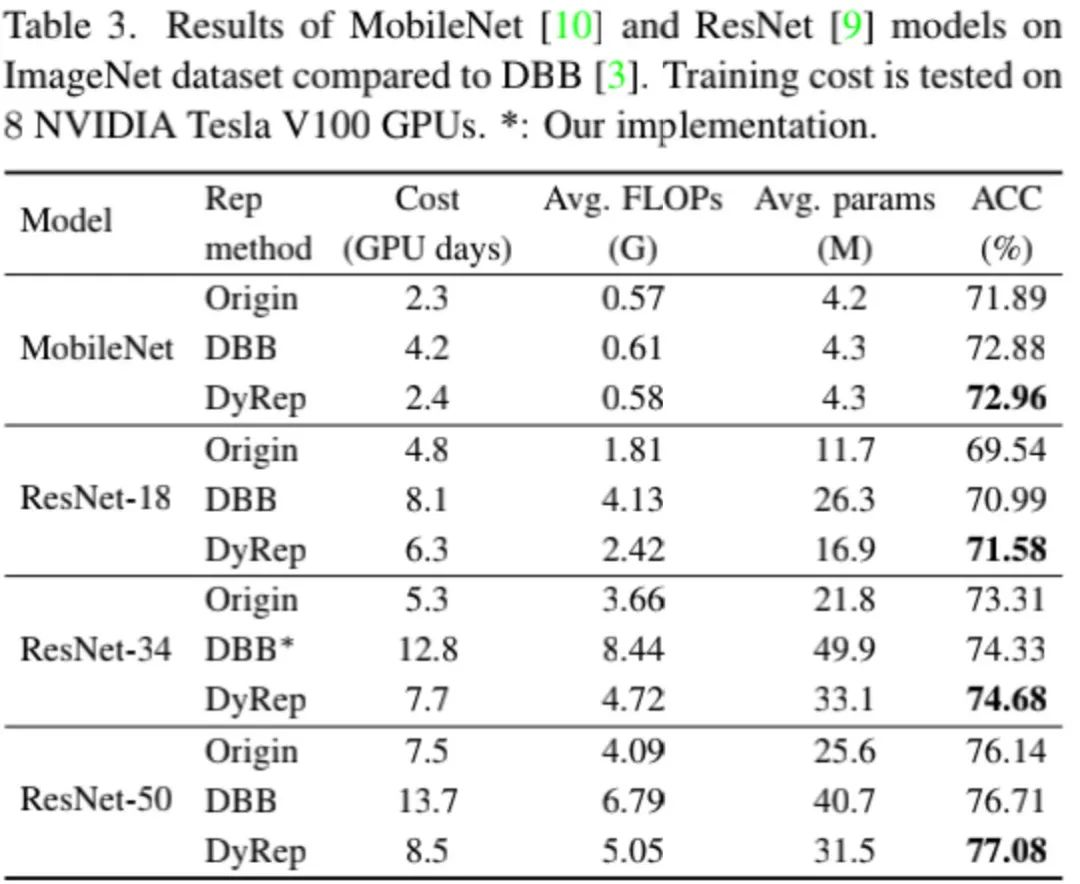
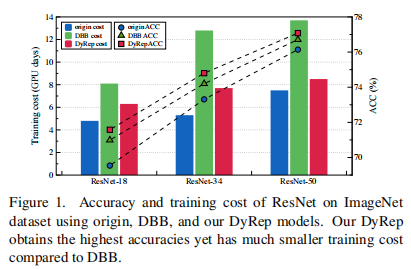
上表给出了ImageNet数据集上ResNet基础模型与DBB与DyRep的性能对比,从中可以看到:相比DBB,DyRep可以取得显著性能提升,同时需要训练耗时更短。
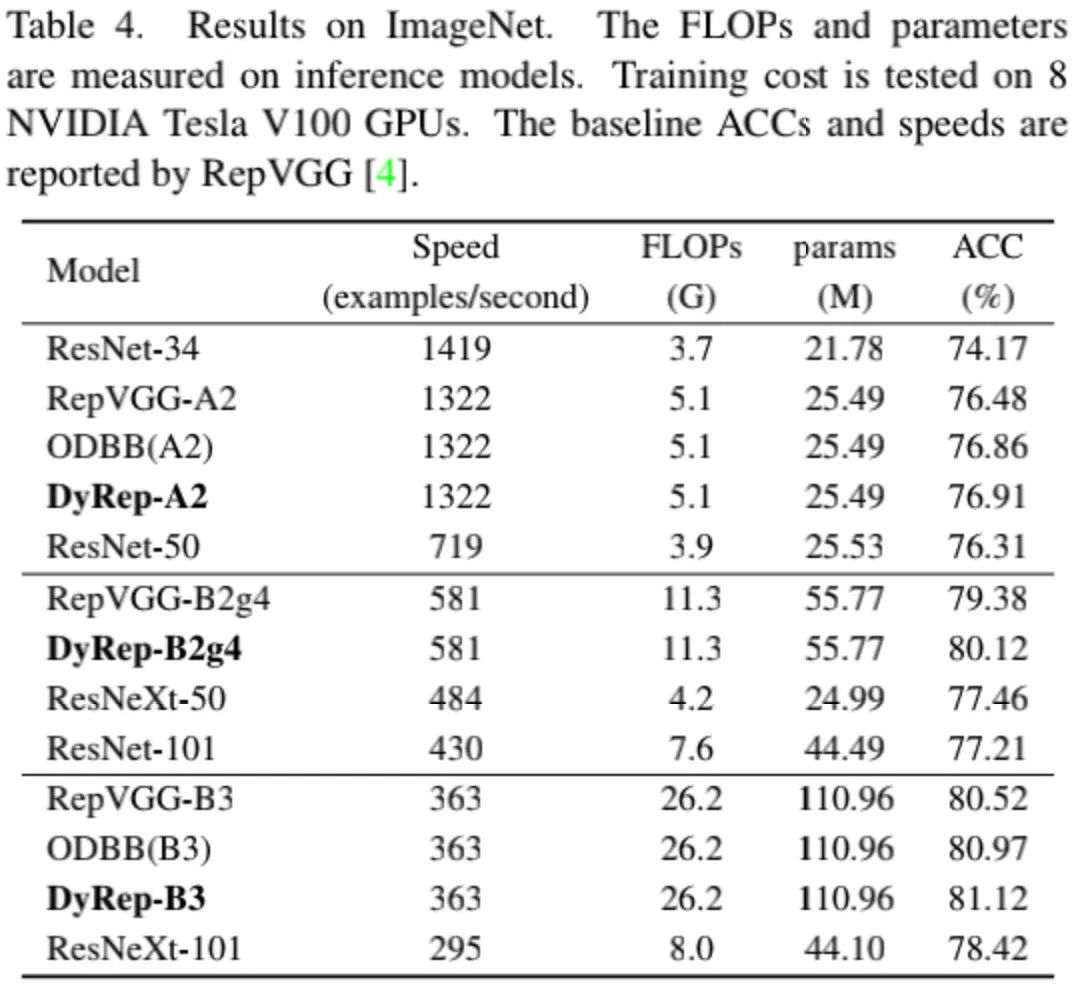
上表给出了所提方案与RepVGG以及RepNAS的性能对比,从中可以看到:相比RepVGG与RepNAS,DyRep取得了更高的精度。
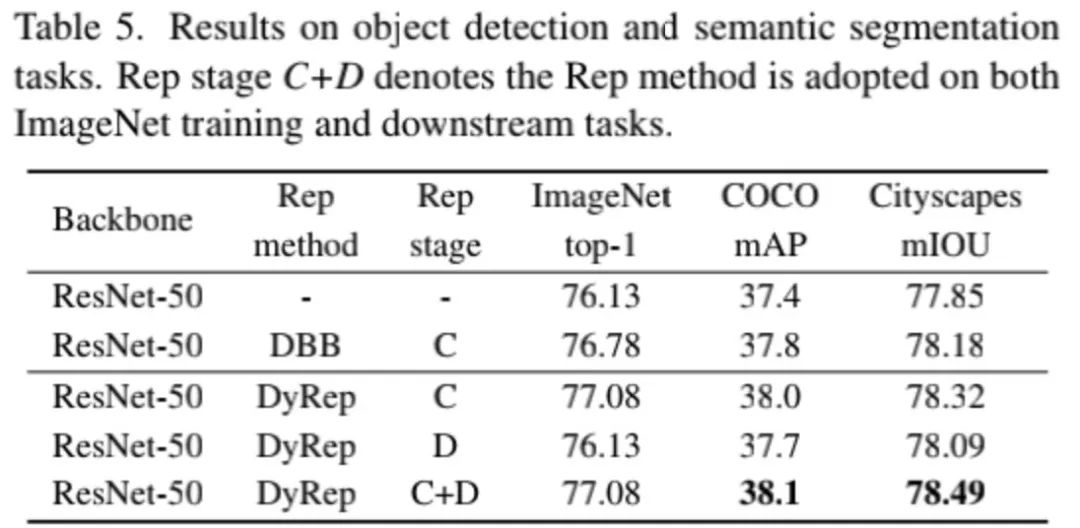
上表给出了下游任务上的性能对比,从中可以看到:相比DBB方案,DyRep可以取得更高的性能提升。
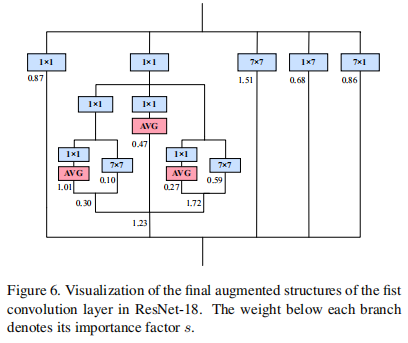
作者同样给出了DyRep重参数化的模型结构,见上图。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢