
作者:Hanlin Tang, Xipeng Zhang, Kai Liu, 等
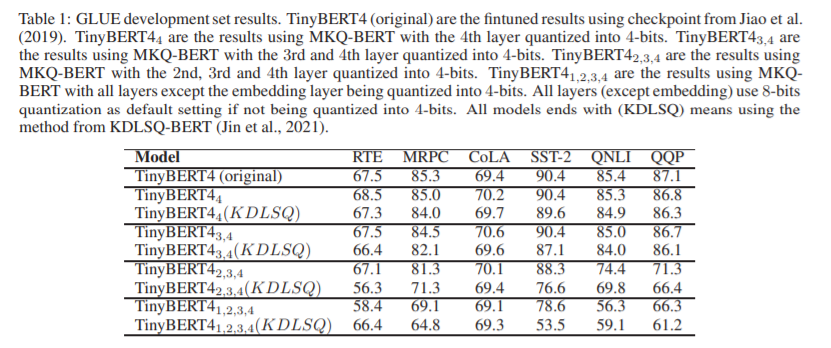
简介:本文研究通过压缩级别的量化方法、以减少BERT模型的计算开销。最近,预训练的基于 Transformer 的语言模型(例如 BERT),在许多自然语言处理 (NLP) 任务中显示出优于传统方法的巨大优势。然而,部署这些模型的计算成本对于资源受限的设备来说是令人望而却步的。减轻这种计算开销的一种方法是将原始模型量化为更少的位表示,之前的工作已经证明,作者最多可以将 BERT 的权重和激活量化为 8 位,而不会降低其性能。在这项工作中,作者提出了 MKQ-BERT,它进一步提高了压缩级别并使用 4 位进行量化。在 MKQ-BERT 中,作者提出了一种计算量化尺度梯度的新方法,并结合了先进的蒸馏策略。一方面,作者证明了 MKQ-BERT 优于现有的 BERT 量化方法,在相同的压缩级别下实现了更高的精度。另一方面,作者是第一个成功部署 4 位 BERT 并实现端到端推理加速的工作。作者的结果表明,作者可以在不降低模型精度的情况下实现 5.3 倍的比特减少,并且在基于 Transformer 的模型中,一个 int4 层的推理速度比 float32 层快 15 倍。
论文下载:https://arxiv.org/pdf/2203.13483
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢