
【论文标题】A Survey of Pretraining on Graphs: Taxonomy, Methods, and Applications
【作者团队】 Jun Xia, Yanqiao Zhu, Yuanqi Du, Stan Z. Li
【发表时间】2022/03/21
【机 构】西湖大学、中科院等
【论文下载】https://arxiv.org/abs/2202.07893v2
【资源下载】https://github.com/junxia97/awesome-pre-training-on-graphs
诸如BERT这样的预训练语言模型(PLMs)已经彻底改变了自然语言处理(NLP)的面貌。受其启发,人们在预训练图模型(PGMs)方面做出了巨大的努力。由于PGMs强大的模型架构,可以从大量有标签和无标签的图数据中获取丰富的知识。隐含在模型参数中的知识可以使各种下游任务受益,并有助于缓解图学习的几个基本问题。在本文中,作者为PGMs提供了第一个全面的综述。本文首先介绍了图表示学习的局限性,从而引入了图预训练的动机。然后,本文根据分类法从四个不同的角度系统地对现有的PGM进行了分类。接下来,本文介绍了PGMs在社会推荐和药物发现中的应用。最后,本文概述了几个有希望的研究方向,可以作为未来研究的指导。
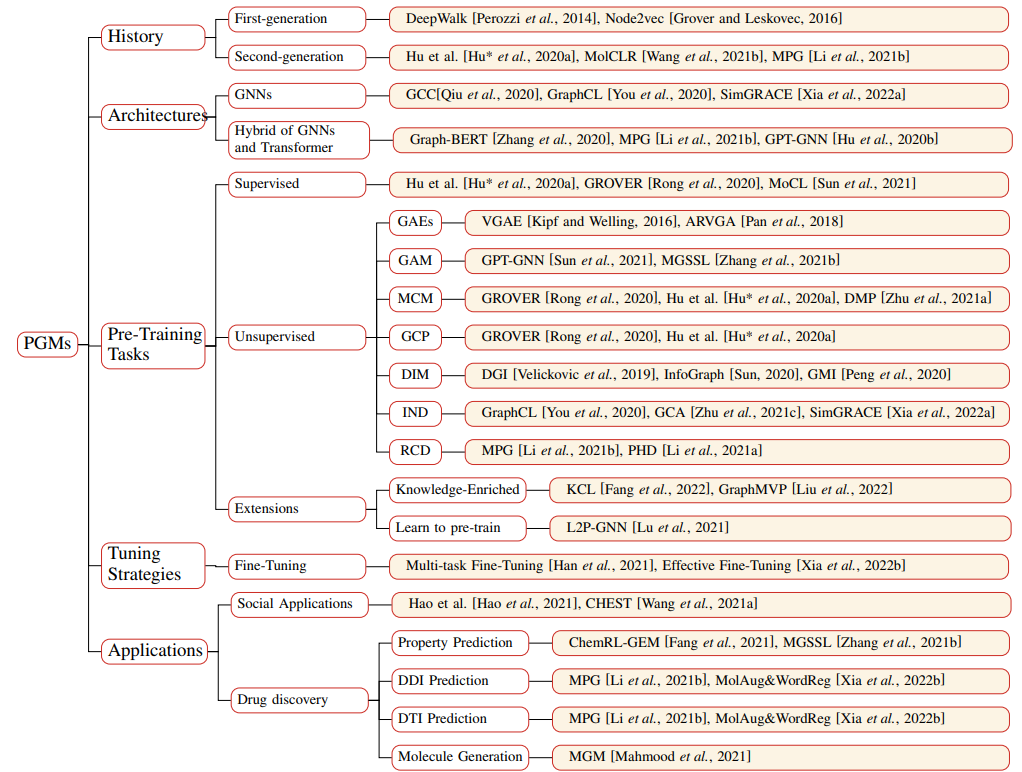
预训练图模型问题的架构,主要分为2代。第一代PGM旨在为各种任务学习良好的图嵌入,如节点聚类、链接预测和可视化,而这些模型本身已不再被下游任务所需要。随着表达式GNN和Transformer的出现,第二代PGM已经接受了迁移学习的设定,目标是预训练一个可以处理不同任务的通用编码器。除了像第一代PGM那样为下游任务学习通用图嵌入外,第二代PGM还可以提供更好的模型初始化,这通常会导致更好的泛化性能,并加速目标任务的收敛。

各种非监督预训练的loss设置,包括:
1.GAE(Graph AutoEncoders):任务为图重建,一种自然的用于学习辨别性的表征的自监督方法,图重建中的预测目标是给定图的某些部分,如节点子集的属性或一对节点之间存在的边。
2.GAM(Graph Autoregressive Model):仿照GPT的范式,给定一个节点和边被随机屏蔽的图,一次生成一个被屏蔽的节点和它的边,并通过最大化当前迭代中生成的节点和边的可能性来优化参数化模型。然后,迭代生成节点和边,直到所有被遮蔽的节点都生成。
3.MCM(Masked Components Model):与遮蔽语言建模(MLM)类似,MCM首先从输入的句子中遮蔽出一些标记,然后训练模型通过其余的标记来预测被遮蔽的标记。
4.GCP(Graph Context Predict):GCP用来探索图数据中的图结构分布,具体做法不同文章有所不同。例如,Hu et al.使用子图来预测它们周围的图结构,作者预训练了一个GNN,使其将出现在类似结构背景下的节点映射到附近的嵌入。 GROVER试图预测一些局部子图中目标节点/边缘的上下文感知属性。
5.IND(Graph Contrastive Learning-Instance Discrimination):IND是最流行的预训练任务之一,它将anchor的增强版本嵌入到正样本之间,并远离其他样本(负样本)的嵌入。对于节点级表示,GRACE及其变体最大限度地提高了节点嵌入在两个损坏的图中的一致性。此外,GraphCL及其变体为图级别预训练提出了各种高级增强策略。
6.DIM(Graph Contrastive Learning-Deep infomax):该方法最初是针对图像提出的,它通过最大化图像表示和图像局部区域之间的相互信息来提高表示的质量。对于图,DGI和InfoGraph通过最大化图级表示和不同粒度的子结构级表示之间的互信息来获得图或节点的表达式表征。
7.RCD(Graph Contrastive Learning-Replaced Component Detection):为了捕捉图的全局信息,RCD被作为输入图的随机排列的图级预训练任务。例如,PHD首先将数据库中的每个分子图分解为两个半图,并将其中一个半图随机替换为其他图的一个半图,对GNN编码器进行预训练,以检测两个半图是否同源匹配。
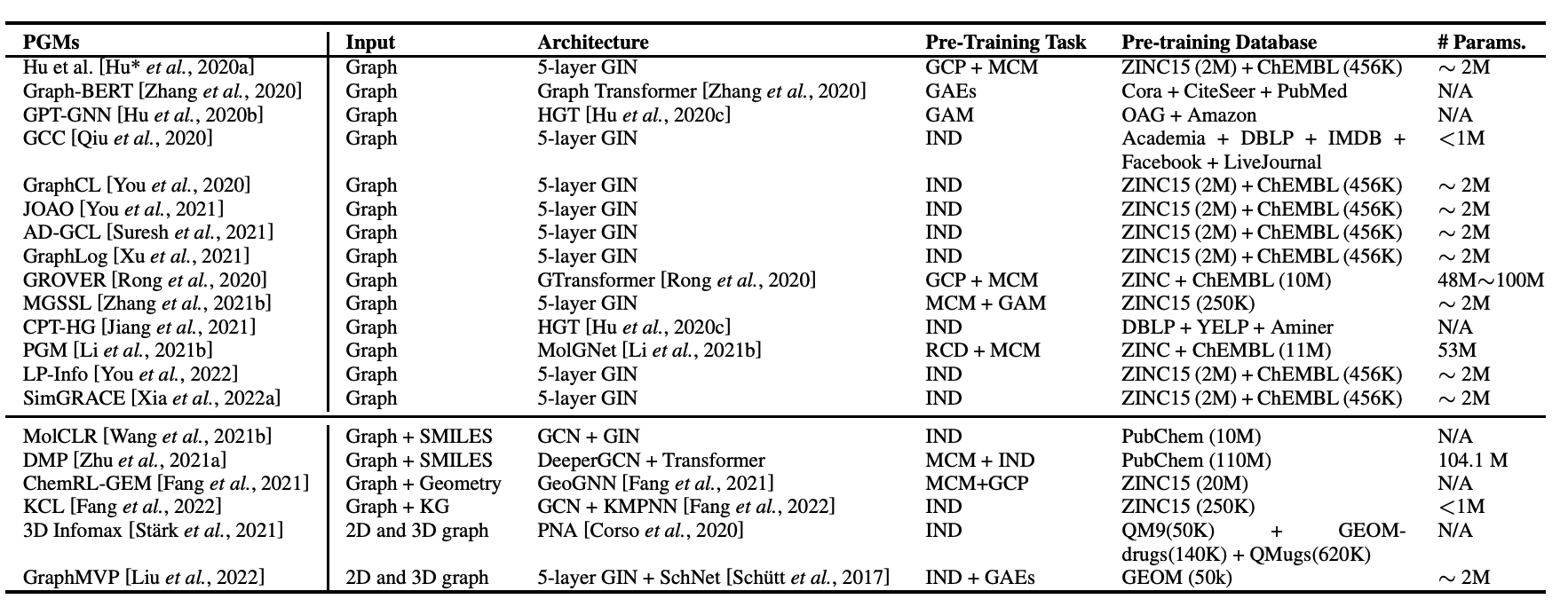
上图展示了PGM的汇总,包含各种应用场景比如化学分子图,推荐图等。其中的一个关键问题就是微调部分,尽管PGMs可以捕获对下游任务有用的反常知识,但微调的过程仍然是很脆弱的,很容易对下游任务的不充分的标签数据进行过拟合。这个问题在生物化学图的构建上尤甚,与图像或文本数据不同,获取生化图数据的标签往往需要进行湿实验,这往往会导致不准确的注释。为了丰富下游任务的标签数据,Xia et al.建议用化学对映体和同源物来增加分子图数据,这些分子与原始分子具有相似的物理(渗透性、溶解性等)或化学(毒性、副作用等)特性。
另一方面,为了控制PGMs的复杂性,研究者引入了一种建立在dropout基础上的新的正则化,希望PGMs的输出在注入一个小的扰动时不要有太大的变化,从而有效地控制PGMs的容量。
此外,在使PGMs适应下游任务时,经常发生灾难性的遗忘。为了缓解这个问题,Han et al.在微调阶段利用元学习来自适应地选择和组合各种辅助任务与目标任务,以实现更好的适应。这保留了由自监督的任务捕获的足够的知识,同时提高了GNN上转移学习的有效性。然而,它将预训练的任务作为前提条件,这阻碍了他们的方法在实践中的使用,因为任务往往是未知的。
在未来,知识迁移、可解释性、更丰富的应用是预训练图的可期待的领域。
本文创新点如下:
1. 全面回顾。本文的调查是第一项对PGMs进行全面回顾的工作。
2. 新的分类法。本文提出了一个新的分类法,它从三个方面对现有的PGM进行分类,并介绍了简史、模型架构、预训练策略、调优策略和在社会推荐和药物发现中的应用。
3.丰富的资源搜集。本文收集了关于PGM的丰富资源,包括PGM的开源实现和论文清单。
4.未来的方向。本文讨论并分析了现有PGMs的局限性。同时,本文还提出了未来可能的研究方向。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢